운영체제 5. 입출력 장치로부터 데이터를 어떻게 가져올까
CPU는 어떻게 동작하는가?
CPU는 그저 멍청하게 정해진 싸이클을 무한 반복하는 연산 장치이다. 어떤 과정을 반복하는가?
- Fetch, 가져오기 : 제어 장치(CU)가 PC 레지스터에 적힌 메모리 주소에서 실행할 명령어를 가져온다. 가져온 명령어는 명령어 레지스터(IR)에 저장한다. 이후 PC 값을 1 증가시킨다.
- Decode, 해독하기 : 제어 장치가 명령어를 분석한다.
- Execute, 실행하기 : 명령어에 따라 작업을 수행한다.
- 연산을 해야하면 ALU에게 넘긴다.
- 메모리를 읽거나 써야한다면 메모리 버스를 사용한다.
- 레지스터에 저장해야 하면 레지스터에 쓰기 신호를 보낸다.
- Go to Fetch
입출력 장치로부터 데이터를 어떻게 읽는가?
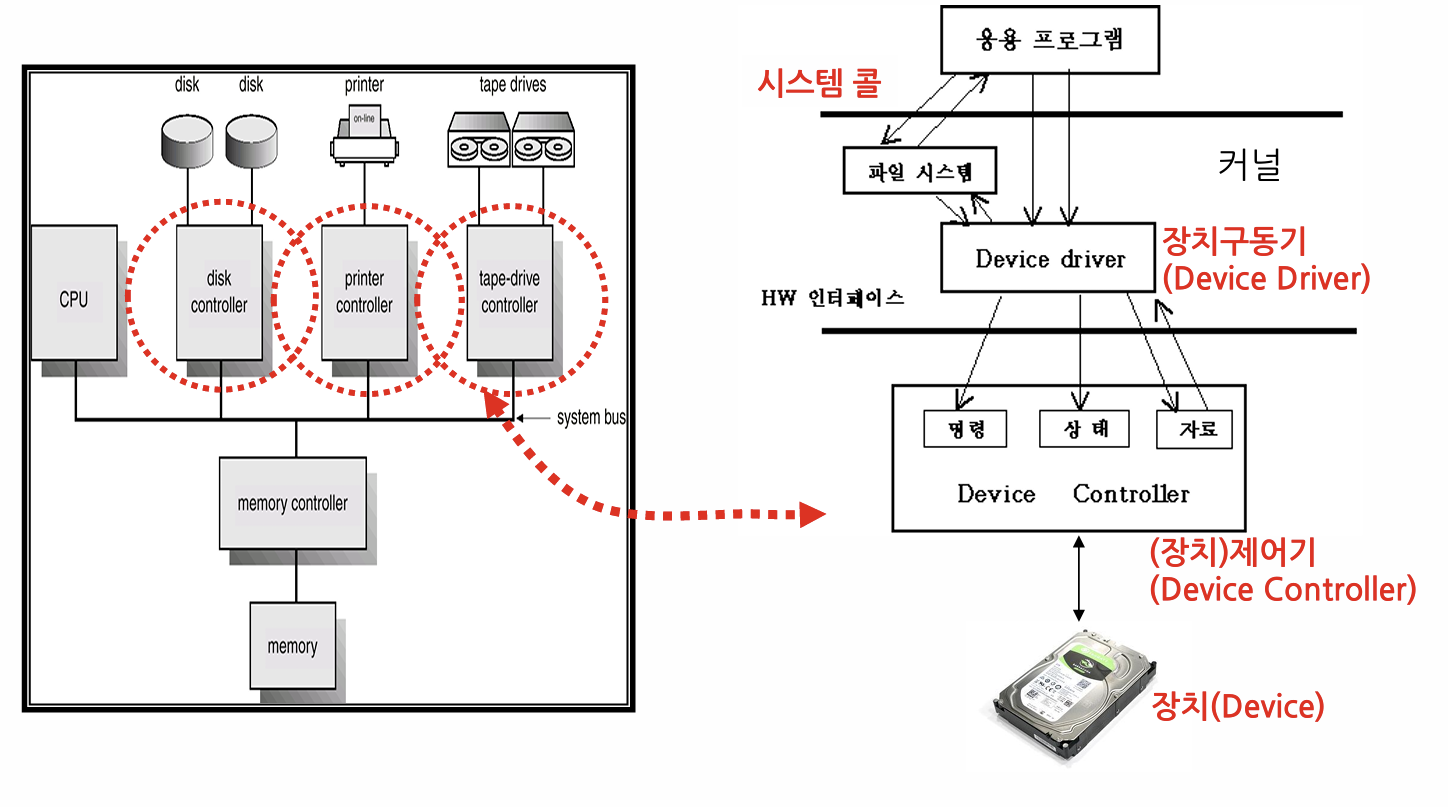
Device Driver가 Device Controller를 통해 Hardware를 제어한다. 이 구조로 덕분에 수없이 많은 종류의 디바이스를 일관적으로 다룰 수 있다.
Device Controller가 무엇인가? Device를 추상화 한 인터페이스와 같다. 실제로는 보드 모양을 하고 있는 하드웨어다. 모든 Software는 Device의 세부 구현을 알지 못해도 Device Controller만 다룰 수 있으면, Device Controller가 하드웨어의 세세한 부분은 알아서 처리한다. Controller는 세개의 레지스터를 가진다.
- 명령 레지스터 : 명령 레지스터에 명령어가 입력되면, 하드웨어는 즉시 동작한다.
- 상태 레지스터 : 명령의 현재 상태, 오류 여부 등은 상태 레지스터에 저장된다. 디바이스 드라이버는 상태 레지스터를 보고 판단할 수 있다.
- 자료 레지스터 : 실제 데이터는 자료 레지스터에 담긴다.
Device Driver가 무엇인가? System Call과 Device Controller 사이의 인터페이스 역할을 하는 소프트웨어다. 소프트웨어는 디바이스 드라이버가 제공해주는 함수만 사용할 줄 알면 디바이스를 제어할 수 있다.
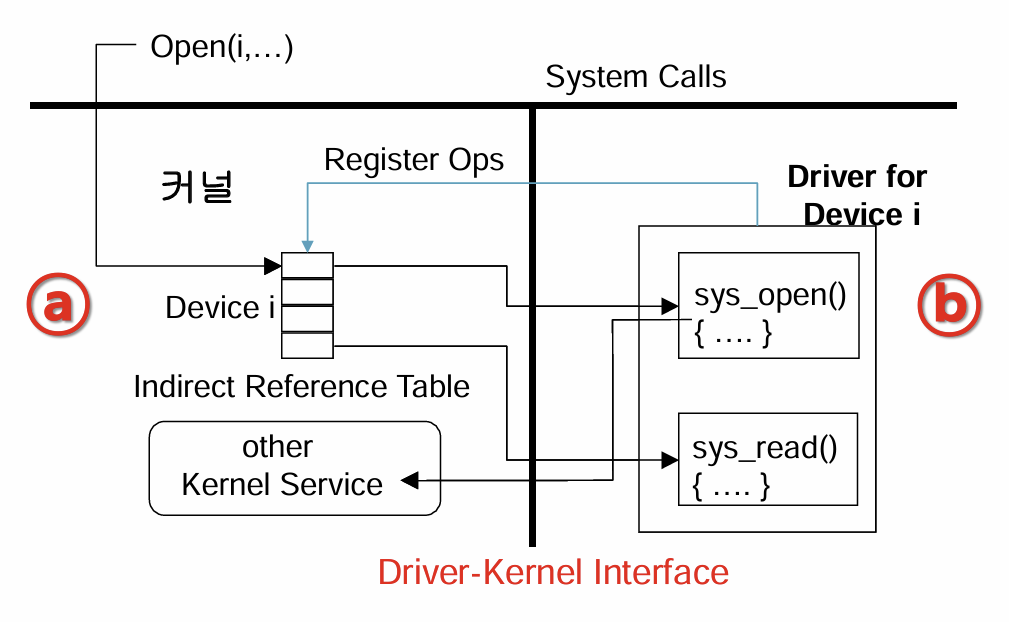
시스템 콜에서 몇번 디바이스에 읽고 쓸건지 정보를 제공해준다. 파일 경로가 그 정보를 담고 있음 디바이스의 Number를 알고 있으면, Indirect Reference Table를 통해 디바이스 드라이버 Table에 접근할 수 있음.
디바이스 드라이버 Table이 뭐냐? 디바이스 드라이버라면 반드시 가져야 할 16개정도의 함수가 정의되어 있음. 우리가 흔히 디바이스 드라이버 소프트웨어를 설치하는 것은, 부팅 시 자동으로 디바이스 드라이버가 커널에 등록되도록 셋팅하는 것. 디바이스 드라이버를 커널에 어떻게 등록하냐? 하면, 커널이 제공하는 디바이스 드라이버 등록 함수가 있다. 디바이스 테이블에 들어갈 필수 함수 포인터를 규격화된 struct에 집어넣어서 함수를 호출하면 커널 내에 디바이스 드라이버 Table이 생성된다.
즉 이 디바이스 드라이버 Table과 필요한 함수의 Index를 알면 디바이스를 제어할 수 있는 함수의 함수 포인터를 얻을 수 있음. 디바이스 드라이버의 함수가 실행됨. 이 과정에서 data trasnfer가 일어남. 이 과정은 아무리 빨라봤자 CPU보다 느림. data transfer가 끝날 때까지 CPU가 기다리면 CPU가 많이 놀게 됨. 따라서 I/O를 할 땐 스케쥴링이 발생함. data transfer가 다 끝났는걸 어떻게 체크하냐에 따라 Polling 방식, 인터럽트 방식으로 구분함.
Polling 방식은 디바이스 드라이버가 디바이스 컨트롤러의 상태 레지스터를 무한 루프를 돌면서/ 체크함. busy상태면 넘어가고, done 상태가 되면 자료 레지스터의 내용을 응용 프로그램 메모리 공간으로 옮김. 계속 루프를 돌기 때문에 CPU가 낭비됨.
인터럽트 방식은 디바이스가 인터럽트를 보내주기 전까지 프로세스를 대기 상태로 전환함. 다른 곳에 CPU 자원을 사용 할 수 있음. 디바이스는 CPU에게 인터럽트를 보내줄 수 있음. 어떻게? 디바이스가 인터럽트를 발생하면 바로 CPU에게 가지는 않음. 발생한 인터럽트는 인터럽트 라인을 타고 인터럽트 컨트롤러에게 전달됨. 인터럽트 라인은 메인보드에 깔려있는 선임. 인터럽트 컨트롤러는 CPU내에 있는건 아니고 메인보드에 있어서 CPU와 연결되어있는 부품임. 인터럽트 라인들은 모두 인터럽트 컨트롤러로 감. (모든 길은 로마로 통하듯이) 인터럽트 컨트롤러는 인터럽트를 여러개 받을 수 있으므로 인터럽트 관리자는 우선순위를 잘 따져서 CPU에게 인터럽트를 하나씩 보냄. 우선순위가 낮은 인터럽트가 들어오면 바로 CPU로 보내지 않는다. 그럼 그 처리되지 않은 인터럽트는 언젠간 처리해야 할텐데, 어디에 대기시켜 놓는가? 인터럽트 컨트롤러가 가지고 있다. 나중에 CPU가 인터럽트 처리를 끝났다는 신호를 인터럽트 컨트롤러에게 보내주는데 (EOI 신호), 그때 우선순위 판단해서 적절한 인터럽트를 CPU에게 보낸다. CPU는 인터럽트를 받으면 하는 일을 바로 멈추고 Context를 백업해둠. 그리고 우선 순위가 낮은 놈이 현재 작업을 끊을 수 없게 마스크를 설정함. 그 마스크는 어디에 저장되는게 가장 좋을까? CPU 자체와 인터럽트 컨트롤러에 각각 저장된다. 기본적으로 마스킹은 인터럽트 컨트롤러가 메인으로 처리한다. 인터럽트 컨트롤러가 마스킹 정보를 보고 CPU에게 인터럽트를 보낼지 말지 결정할 수 있다. 간혹 CPU가 아주 중요한 일을 처리해야 할 때는 CPU 자체에 들어있는 마스크(Flag)를 켜서 아무 인터럽트도 받지 못하게 할 수 있다. CPU가 하고 있는 일은 프로세스를 돌리고 있거나 인터럽트를 처리하고 있거나 둘 중 하나임. 만약 우선순위가 높은 인터럽트를 처리중이라면 인터럽트가 발생해도 바로 처리되지 않을 수 있음. 이후 그 인터럽트에 대한 ISR을 실행함. ISR의 메인 함수의 함수 포인터는 Interrupt Descript Table를 보면 얻을 수 있음. ISR는 인터럽트 처리를 다 끝내면 기존의 Context를 복구하고 스케쥴링함. 바로 실행하지 않고 스케쥴링하는 이유는, 인터럽트 처리 과정에서 우선순위가 어떻게 바꼈는지 모르기 때문임.
그럼 무조건 인터럽트 방식이 좋은 것 아니냐? 인터럽트 방식은 오버헤드가 살짝 있음. 만약 대기시간이 아주 짧다면 간단하게 Polling 방법을 써도 나쁘지 않음. 또, 하드웨어 자체에서 인터럽트를 보내줘야 하기 때문에 인터럽트 발생 기능이 없는 디바이스면 폴링 방식으로 구현할 수 밖에 없음.
시스템 콜은 data transfer 과정을 기다리다가 다 끝났을 때 데이터를 리턴하던가, 기다리지 않고 함수를 바로 리턴해서 나중에 인터럽트를 받으면 지정해둔 콜백 함수를 실행하던가 두가지 방법을 선택할 수 있음. 첫번째를 Blocking call, 동기식 호출이라고 함. 두번째 방법은 non-blocking call, 비동기식 호출이라고 함.
Blocking call vs Non-blocking call과 Polling vs Interrupt는 같은건가?
전자는 System Call 수준의 얘기고 후자는 I/O에서 디바이스 처리 수준에 대한 얘기다. ‘Blocking call을 할거냐 Non-blocking call을 할거냐’는 시스템 콜에서 결정한다. Blocking call은 I/O 과정이 끝날 때까지 프로세스를 Blocking 상태로 바꿔두고,
ISR이 하는 일은 무엇인가?
ISR은 CPU가 I/O 디바이스에게 인터럽트를 받으면, 그 디바이스에 대응하는 인터럽트 처리 프로그램을 실행한다. 그 프로그램이 ISR이다. 인터럽트는 인터럽트 Number와 같이 보내지는데, 이 Number를 통해 CPU는 Interrupt Descriptor Table에 접근하여 ISR의 시작 포인터 주소를 얻어낼 수 있다.
위 IDT는 언제 만들어지는가? 부팅 과정에서 디바이스 드라이버에 의해 셋팅된다. 디바이스 드라이버는 컴퓨터가 부팅되면 커널에 붙고, 그 과정에서 ISR 프로그램을 Table에 적재한다. 그럼, ISR에서 처리해야 하는 작업이 뭘까? I/O 인터럽트란 I/O 장치가 Data Transfer이 종료되었을 때 발생한다. 이 인터럽트가 발생했다면 기존의 Blocking 해뒀던 프로세스가 다시 Ready 상태로 바뀌어야 한다. 그렇다면 ISR에서 Blocking 해뒀던 프로세스를 찾아서 Ready 상태로 바꾸는 작업을 해야한다는건데, Blocking 중인 프로세스가 한두개가 아닐텐데 어떻게 해당 I/O와 관련된 프로세스를 딱 찝어서 Ready상태로 전환시킬까?
Blocking된 프로세스는 Blocking Queue에 들어가있다. 정확히는 Waiting List라고 부르는 것이 더 좋을 수 있다. Blocking Queue에는 우선순위 개념이 없으니까. Blocking Queue는 커널 내에 글로벌로 하나만 존재하지 않는다. 각 디바이스마다 하나씩 Blocking Queue를 갖고 있을 수 있고, 특정 이벤트 별로 Blocking Queue를 또 따로 가질 수도 있다.
프로세스에서 어떤 디바이스를 사용할 때, Blocking 상태로 전환할 때 그 디바이스에 대응하는 Blocking Queue에 본인의 PCB를 넣는다. 이후 디바이스 ISR에선 본인 디바이스에 해당하는 Blocking Queue에 접근하여 해당 프로세스를 깨운다. 그렇다면, 이런 의문점이 생긴다. 두개의 프로세스가 한 디바이스에 동시에 접근하여, Blocking Queue에 여러 프로세스가 있다면 어떻게 처리해야 하는가? Request ID와 같은 숫자를 인터럽트와 같이 주고받으면 해결된다. 다음과 같은 작업 처리가 이루어진다.
- 프로세스가 I/O에 접근하는 시스템 콜을 호출한다.
- 시스템 콜 내에선 그 작업에 대한 Request ID를 생성하고 I/O를 처리하고, 기다리는 동안 Blocking 상태로 전환한다.
- 디바이스가 작업이 끝나면 인터럽트
(Request ID가 포함됨)를 발생한다. - CPU는 인터럽트를 받아 ISR을 실행한다.
- ISR에선 전달된 Request ID를 알고 있고, 현재 디바이스와 관련된 Blocking Queue에 접근할 수 있다. Ruquest ID로 Blocking했던 프로세스를 Blocking Queue에서 찾아서 해당 프로세스를 다시 Ready 상태로 전환한다.
- 스케쥴링!
CPU는 디바이스 컨트롤러의 레지스터에 어떻게 접근하는가?
디바이스 컨트롤러는 디바이스가 포함하고있는 하드웨어다. CPU는 메모리에는 Memory Bus를 통해 접근이 가능하다. 그러나 따로 분리되어있는 디바이스 내의 레지스터는 어떻게 사용할 수 있는가? 사용 방법은 레지스터 직접 접근 방식과, 메모리 Mapped 두가지 방법이 존재한다.
먼저 레지스터 직접 접근 방식 (Isolated I/O) 은 메모리와 같이 레지스터를 위한 별도의 주소공간을 사용하는 방식이다. 이를 Isolated Address Space라고 한다. Isolated Address Space에 접근하기 위한 명령어는 메모리에 접근하는 명령어와 별도의 명령어를 사용해야 한다. 이 방법은 직접 레지스터에 접근하기 때문에 Main memory의 공간을 절약할 수 있다. 하지만 별도의 명령어를 사용하기 때문에 구현이 귀찮다.
Memory-Mapped 방식은 메인 메모리의 일부 공간을 디바이스 컨트롤러의 레지스터와 동기화 하자. 이렇게 하면 CPU 입장에선 디바이스 레지스터에 접근할 때 별도의 명령어를 사용하지 않고 그냥 메모리 접근하듯 디바이스 컨트롤러의 레지스터를 사용할 수 있다. 접근성이 좋아지지만, Memory Mapped에 의한 약간의 오버헤드와 메인 메모리 영역이 살짝 줄어든다. 현재 가장 많이 사용하고 있는 방법이라고 한다.

디바이스 컨트롤러 자료 레지스터에 저장된 데이터는 어떻게 메인 메모리로 이동하는가?
두가지 방법이 존재한다. CPU가 직접 디바이스 컨트롤러에 접근하는 명령어를 사용해서 메인 메모리로 옮기는 방법과, 별도의 하드웨어를 하나 도입해 Main Memory와 디바이스 사이를 다이렉트로 데이터를 옮기는 것.
전자의 방법이 직접 입출력 방식이다. 데이터가 크지 않은 마우스, 키보드와 같은 Character Device의 경우는 CPU가 직접처리해도 무방하다. 하지만 HDD와 같이 주고받는 자료가 큰 Block Device와 같은 경우는 문제가 있다. 자료가 크기 때문에 여러번 나눠서 처리할 수 밖에 없는데, 그 과정을 모두 CPU가 관여해도 되지만 더 효율적인 방법이 있다.
두번째 방법이 DMA(Direct Memory Access) 방식이다. 메모리는 물리적으로 한 순간에 두 장치에서 동시에 접근할 수 없다. 따라서 메모리 접근 권한은 기본적으로 CPU가 가지고 있다. 메모리 접근 권한이랑, 메모리로 가는 System Bus의 접근 권한과 같다. 장치에서 자료를 메모리로 옮겨야 할 일이 생기면 DMA 컨트롤러가 CPU에게 요청하여 한 싸이클동안 메모리를 사용할 수 있는 권한을 얻는다. DMA는 메모리를 다 사용하면 CPU에게 인터럽트를 보낸다. CPU 입장에선 여러번의 인터럽트를 처리해야 했던게 한번의 인터럽트로 줄었으므로 효율적이다.
그런데 궁금한 점. 자료가 너무 커서 CPU의 한 싸이클동안 자료를 다 처리 못하는 경우는 어떻게 하는가? CPU의 사이클은 정확히 한 싸이클만 쉬다가 다시 뺏어오는가? DMA가 인터럽트를 보내줄 때까지 무기한 양보하는가? 만약 무기한 양보하면 DMA가 인터럽트를 보내주지 않으면 CPU는 영원히 쉬게 되는 것 아닌가?
DMA에게 메모리 접근 권한을 얻기 위한 여러 모드가 존재함을 이해해야 한다.
- Cycle Stealing Mode : CPU를 딱 한 싸이클동안 쉬게 한다. 아주 짧은 시간이기 때문에, 주고받는 데이터는 1~8 바이트밖에 되지 않는다.
- Burst Mode : DMA 컨트롤러가 모든 데이터를 읽거나 쓸 때까지 계속 권한을 넘겨주는 방식. CPU가 좀 놀지만, 세 모드 중 전송 속도가 가장 빠르다.
- Transparent Mode : CPU가 메모리를 사용하지 않는 순간에만 DMA가 메모리에 접근하는 방식. CPU를 극한까지 뽑아먹지만, 세 모드 중 가장 전송 속도가 느리다.
따라서 자료가 너무 크면 Burst Mode를 사용하면 되고, CPU 사이클은 Cycle Stealing Mode일 경우 정확히 한 싸이클만 쉬게 된다. DMA 컨트롤러는 작업을 끝내던, 오류가 나던 반드시 인터럽트를 보내주기 때문에 CPU가 영원히 쉴 일은 없다.
인터럽트 마스크는 어떻게 동작하는가?
인터럽트가 발생되면, 인터럽트 컨트롤러는 현재 인터럽트 마스크와 비교하여 블락이 안되어있다면 바로 CPU에게 보내 기존의 작업(프로세스, 인터럽트 처리)을 즉시 중단하게 만든다. 블락이 되어있다면, 대기했다가 인터럽트 처리가 끝났다는 신호가 CPU에게 들어오면 기존의 인터럽트 마스크를 재설정 후 대기중이던 인터럽트를 처리하기 시작한다.
CPU가 인터럽트를 받으면, 인터럽트 루틴을 실행한다.
- 현재 작업중인 프로세스 또는 ISR을 즉시 중단한다.
- CPU 레지스터 Context를 저장한다. 여기까지가 CPU 하드웨어에서 최소한으로 일어나는 동작이다. 이후 인터럽트 처리를 위한 커널 내의 인터럽트 핸들러 시작 주소로 이동한다.
- 완전한 Context를 백업한다.
- 인터럽트 벡터
(인터럽트 넘버)를 확인하여 그 인터럽트에게 미리 정의된 인터럽트 마스크를 인터럽트 컨트롤러의 인터럽트 마스크 레지스터에 씌운다. - ISR을 실행한다. 이후 ISR 실행이 끝나면, 다시 커널의 인터럽트 핸들러로 복귀한다.
- 인터럽트 마스크를 복구한다.
- 저장했던 Context를 복구한다.
- 스케쥴링을 하거나, 원래 실행중인 작업을 다시 처리하도록 한다.
(운영체제 정책에 따라 다름)
모든 장치는 우선순위 비트 넘버를 부여받는다. 인터럽트 컨트롤러는 이 인터럽트의 비트 번호와 인터럽트 마스크를 AND 연산하여 False가 나오면 새로 들어온 인터럽트를 처리한다. True라면, 현재 이 인터럽트가 Blocking 되었다는 것을 의미한다. 따라서 당장에 처리하지 않는다.
예를들어 Device 1가 \(00000100\) 우선순위 비트 넘버를 가지고, 현재 마스크가 \(00100100\)으로 설정되었다고 가정하자. 비트의 AND 연산은 각 비트 자리수끼리 비교하여 둘다 1이면 1이고 그렇지 않으면 0이다. 따라서 자릿수가 하나라도 같으면 True가 나오고, 전부 다르다면 False가 나온다. 위 상황의 경우 AND 연산하면 \(00000100\)이고, True가 나왔으므로 현재 이 인터럽트는 Blocking 중인 것과 같다. 따라서 처리되지 않는다.
만약 우선순위 비트 넘버가 \(00100000\)이라면, AND 연산 결과는 \(00000000\)이므로 False와 같다. 이 경우는 인터럽트가 즉시 처리되며 인터럽트 마스크도 새롭게 업데이트 될 것이다.
수준(Level) 에 따라 인터럽트가 처리될 수도 있고 처리되지 않을 수도 있다. 이러한 인터럽트를 다수준 인터럽트라고 한다. clock interrupt와 같이 다른 인터럽트 다 제끼고 그 시간에 반드시 실행되어야 하는 (Time Critical) 인터럽트가 존재할 수 있다. 이런 인터럽트는 Fast Interrupt로, 바로 실행되도록 구현한다. 하지만 Clock interrupt의 경우 시스템 프로그래밍 시간에 배웠듯이, Tick count만 증가시키는게 아니다. 커널은 Passive하기 때문에, 누가 실행해주기만을 오매불망 기다리다가 실행되면 밀려있던 작업을 한번에 처리(스케쥴링, 루틴 등...) 하는 경향이 있다. 그러면 커널을 아무도 안불러주면 작업을 처리하지 못하기 때문에, Clock Interrupt마다 커널을 실행하여 이 문제를 해결한다. Tick Count를 증가시키는 일은 Time Critical하지만, 나머지 일은 딱히.. 그정도 까진 아니다. 때문에 Tick Count 작업과 나머지 일을 Top-half와 Bottom-half로 분리한다. Top-half는 바로 실행되어야 하는 작업이고, Bottom-half 작업은 다수준 인터럽트와 같이 처리되는 작업이다.