운영체제 17. 동기화를 어떻게 구현할까 - Mutex, Semaphore
동기화가 무엇인가?
동기화(Synchronization)란, 여러 프로세스가 공유 영역에 동시에 접근할 때 한명씩 접근하도록 만드는 방법이다. 한명씩 접근하는 것을 순서화(Serialize)한다고 한다.
왜 동기화가 필요한가? Race Condition을 방지하기 위해서다. 공유된 자료구조에 여러 프로세스가 동시에 Write하면 의도한 동작이 아닌 다른 결과가 생길 수 있다. 이를 Race Condition이라 한다.
[!question]- 왜 Race Condition이 발생하는가?{title} 어셈블리 코드 수준에서 살펴보면 이해할 수 있다.
위 코드를 두 쓰레드에서 동시에 실행한다고 해보자. 위 코드를 기계어에선 세 줄로 표현된다.
- 메모리에 쓰여진 값을 레지스터로 옮기고
- 레지스터 값을 1 더한 뒤,
- 레지스터 값을 메모리에 다시 쓴다.
만약 쓰레드 1에서 2번까지만 실행하고, Context Switch가 발생했다고 치자. 쓰레드 2에서 같은 코드를 실행하여 n의 값을 1 증가시킨다. 다시 쓰레드 1이 실행되면, 2번까지 실행되었을 때 값이 덮어씌워진다. 즉, 원래대로라면 n의 값이 2 증가되어야 하는데 덮어씌워져서 1만 증가하게 된다.
어떻게 동기화하는가? 먼저, 공유 데이터를 사용하는 코드 블럭을 임계 구역(Critical Section)으로 설정한다. 어떤 프로세스가 해당 공유 데이터에 대한 임계 구역을 실행하고 있으면, 다른 곳에서 임계 구역을 실행할 수 없도록 제한한다. 이렇게 동기화하면 Context Switch가 언제 일어나도 간섭 없는 원초적(Atomic) 실행이 보장된다.
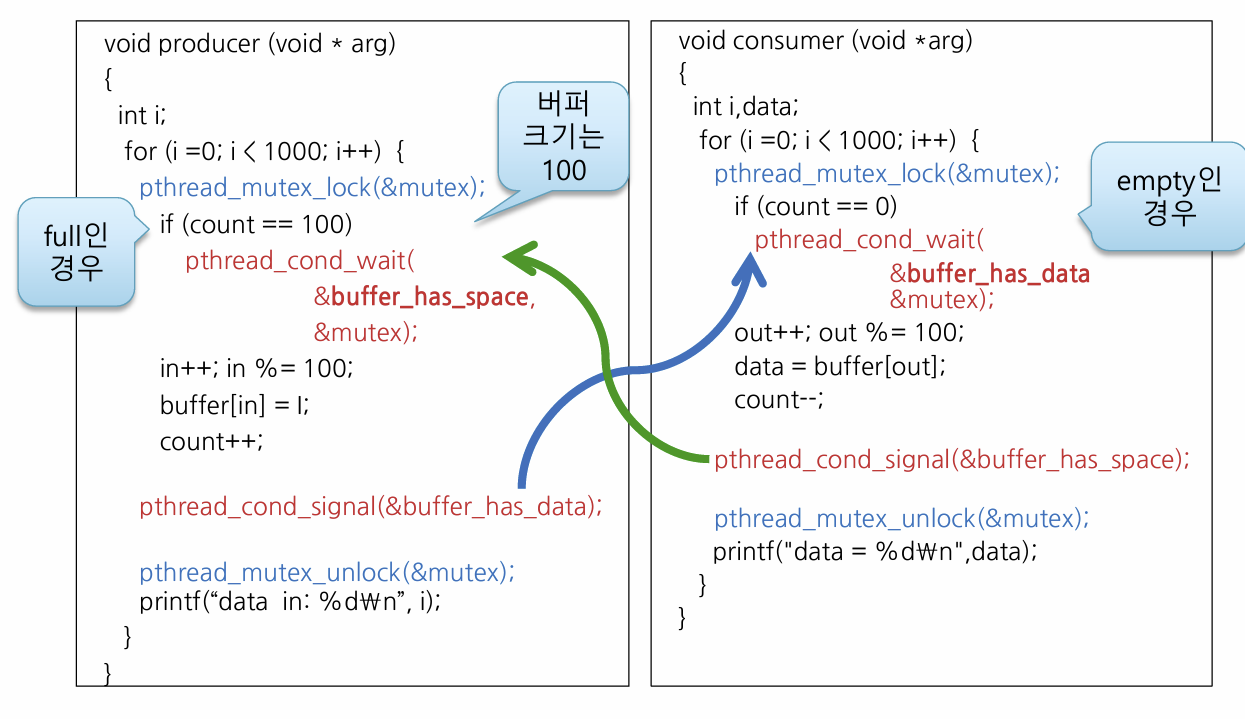
[!example]- Mutex 변수를 사용한 예제 코드{title}
임계 구역을 진입할 때 Mutex를 Lock 걸고, 빠져나올 때 Unlock을 하면 Lock걸려있을 때 다른 곳에서 Lock 걸어둔 Mutex 임계구역에 접근할 수 없다.
위 코드에선 두개의
pthread_cond_t buffer_has_space, buffer_has_data를 만들어두었다.pthread_cond_wait,pthread_cond_signal은 뭐고, 왜 쓰는걸까?위 코드는 생산자에서 데이터를 만들고 소비자에서 데이터를 받는 코드다.
pthread_cond_wait(&buffer_has_space, &mutex)는&buffer_has_space에 대한 시그널이 들어올 때까지 Mutex Lock을 잠깐 풀어두고 쓰레드를 Block 한다. 시그널이 들어오면 Mutex가 다시 잠기고 쓰레드가 깨어난다. 마찬가지로pthread_cond_wait(&buffer_has_data, &mutex)또한 동일하다. 왜 Lock을 잠깐 풀어둬야 할까?만약 소비자가 먼저 실행되면, Mutex를 잠구고 데이터가 들어올 때까지 busy waiting 하게 된다. 그런데 생산자에서 버퍼에 쓰려면 임계구역 내에 들어가야 하는데, 소비자가 잠가둬서 들어갈 수 없다. 따라서 한쪽은 무한 busy waiting하고, 한쪽은 들어갈 수 없는 상황이 만들어진다. 따라서, busy waiting하는 동안 Mutex 잠금을 잠깐 풀어줘야 정상적으로 작동할 수 있다.
반대로 생산자가 먼저 실행되면? count를 증가하는 도중에 Context Switch가 일어날 수 있다. 이때 소비자가 실행되면 mutex lock이 걸려있기 때문에 공유 데이터에 접근할 수 없다. 이 경우 문제되지 않는다.
count ** 100이 되는 경우, 소비자에서 데이터를 가져갈 때까지 생산자는 busy waiting한다. 그러나 소비자에서 데이터를 가져가려면 공유데이터에 접근해야 하는데, 생산자가 Lock을 걸어뒀기 때문에 접근할 수 없다. 따라서,count ** 100후 busy waiting할 때 Mutex 잠금을 잠깐 풀어둬야 소비자에서 데이터를 가져갈 수 있다.[!question] 그런데 busy waiting 해야하는데 왜 while이 아니라 if인가?{title} pthread_cont_wait를 실행하면 쓰레드가 block되기 때문이다. 그러나 안정성을 위해 while 루프 안에서 호출되는 것을 권장한다고 한다.
그렇다면..
동기화는 어떻게 구현되어 있을까?
한 프로세스가 임계구역을 실행하고 있으면, 다른 프로세스는 임계구역에 접근할 수 없도록 설정해야 한다. 그 과정에서 간섭이 발생하면 안된다. 이 성질이 mutual exclusion이다.
동기화를 지원하는 도구는 Mutex와 Semapore가 있다.
Mutex를 어떻게 구현하는가?
소프트웨어 수준에서 구현하는 세가지 방법과, 하드웨어 수준에서 구현하는 세가지 방법이 존재한다.
(SW) Lock Test
진입할 때 변수값이 true인지 체크한다. true가 아니면, 변수를 true로 바꾼다. 나올 때 변수를 false로 바꾼다. 결론적으로, 이 방법은 사용할 수 없다.
그 이유가 무엇일까? 변수가 true인지 체크하고난 이후 Context switch가 발생하면, 현재 변수값이 False이므로 다른곳에서도 임계 구역에 진입할 수 있다. 이후 원래 프로세스로 돌아오면 임계 구역에 프로세스가 동시에 접근했다. mutual exclusion 성질이 깨졌다.
[!example] 코드{title}
(SW) Peterson’s Solution
두 사람이 있고, 서로 딱 한번씩 양보하면 항상 먼저 양보한 사람이 먼저 들어간다. 따라서 진입이 순서화된다. 따라서 동기화된다.
코드 구현은 어떻게 하는가? 임계구역 진입 여부를 나타내는 변수 flag와, 누구 턴인지 나타내는 turn 변수가 필요하다.
진입하면, 본인 Index에 해당하는 진입 여부 변수를 True로 바꾼다. 그리고 Turn을 상대에게 넘긴다. 간섭은 언제 발생 가능할까? 상대가 진입했는데, 턴이 오지 않는 경우와 같다. 즉, 상대가 진입했지만 아직 턴이 오지 않았을 때 대기한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
int turn = 0;
boolean flag[] = {0, 0};
enter_mutex_i {
flag[i] = true;
turn = j;
while (flag[j] && turn == j);
}
enter_mutex_j {
flag[j] = true;
turn = i;
while (flag[i] && turn == j);
}
exit_mutex(index) {
flag[index] = false;
}
위 코드는 문제가 없는가? 문제가 없다면, 그것을 어떻게 증명하는가? 만약 둘 중 혼자만 진입했다고 가정하자. 이 경우 상대가 진입하지 않았으므로 flag 변수가 false라 대기하지 않는다. 바로 임계구역에 진입한다.
만약 둘이 동시에 진입했다고 가정하자. 이 경우 두 flag 변수가 모두 true로 설정된다. turn 변수는 반드시 i 또는 j다. 따라서 둘 중 하나는 반드시 대기하고, 둘 중 하나는 반드시 임계구역에 진입한다. 따라서 간섭이 발생하지 않는다.
Lamport (Bakery 알고리즘)
Perterson’s Solution은 두개의 프로세스에 한에서만 사용 가능하다. 이를 다중 프로세스로 확장하기 위해 은행 번호표 아이디어를 사용한다.
프로세스가 임계구역에 진입하려면 번호표를 받는다. 번호표가 작은 순서대로 임계 구역을 사용할 수 있다. PID를 i, n을 총 프로세스 수라고 하자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
entey_mutex {
// 번호표를 뽑는다.
number[i] = max(number[0], number[1], ..., number[n-1]) + 1;
// 모든 번호표 중 number[i]가 가장 작아질 때까지 대기한다.
// 만약 간섭에 의해 번호표가 같아진다면, PID가 작은 것을 먼저 처리하자.
for (j = 0; j < n-1; j++) {
while (number[i] < number[j] || number[i] == number[j] && j < i);
}
}
exit_mutex {
number[i] = 0;
}
number[i] 값을 Write하기 전 Context Switch가 발생하면, 두 프로세스의 number 값이 같아질 수 있다. 따라서, 이 경우까지 고려해야 한다. j < i든, i < j든 상관 없다. 누가 먼저 진입할 것인지 그 순서만 정해주면 된다.
위 코드의 문제점이 있다. number[i]를 Write하기 전 Context Switch가 발생하고, 다른 프로세스에서 number[i]를 Read할 때 Write하기 전 값을 Read해갈 수 있다. 따라서, 내부적으로도 임계구역을 설정해서 동기화해야 한다. 동기화 변수 choosing[i]를 도입한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
entey_mutex {
// 번호표를 뽑는다.
choosing[i] = true;
number[i] = max(number[0], number[1], ..., number[n-1]) + 1;
choosing[i] = false;
// 모든 번호표 중 number[i]가 가장 작아질 때까지 대기한다.
// 만약 간섭에 의해 번호표가 같아진다면, PID가 작은 것을 먼저 처리하자.
for (j = 0; j < n-1; j++) {
// 번호를 뽑을 때까지 대기한다. 잘못된 값 Read 방지.
while (choosing[j]);
while (number[i] < number[j] || number[i] == number[j] && j < i);
}
}
exit_mutex {
number[i] = 0;
}
번호표 뽑는 것을 동기화함으로써 number[i] == number[j] && j < i 조건을 체크하지 않아도 되는 것 아닌가? 그렇지 않다. 번호표를 뽑는 매커니즘에서 busy waiting이 없으므로 간섭이 여전히 발생할 수 있다.
(HW) test-and-set
하드웨어 수준에서 두가지 명령어를 동시에 수행하여 원자성을 보장한다. Race Condition이 어디에서 발생하는가? 어셈블리 코드에서 메모리에서 레지스터로 값을 불러오고, 레지스터의 값을 증가하하고, 그 값을 메모리에 Write하는 과정 사이에서 발생할 수 있다. 반대로, 위 과정을 Atomic하게 실행 가능하면 Race Condition을 방지할 수 있다.
즉, 메모리에서 값을 가져오고, 그 메모리의 값을 Atomic하게 설정할 수 있다면? 이 명령어가 test-and-set 명령어다.
- Test: 메모리에서 값을 읽고
- Set: 그 메모리의 값을 1로 설정한다.
1
2
3
4
5
6
7
int Test-and-Set(int *target)
{
int temp;
temp = *target; // 값을 읽고
*target = 1; // true로 설정한다.
return temp;
}
이를 통해 mutex를 구현할 수 있다. 공유 변수를 test-and-set 명령어로 1로 설정하면 된다.
1
2
3
4
5
6
7
8
9
lock = 0; // 공유 변수
entry_mutex {
while (Test-and-Set(&lock));
}
exit_mutex {
lock = 0;
}
(HW) Swap
1
2
3
4
5
6
7
void Swap(int *a, int *b)
{
int temp;
temp = *a;
*a = *b;
*b = temp;
}
Swap을 Atomic하게 실행할 수 있다면 Mutex를 구현할 수 있다. 어떻게 구현할까? Swap을 Atomic하게 실행할 수 있다는 뜻은, 메모리에 값을 읽고 그 메모리의 값을 특정 값으로 설정하는 작업을 Atomic하게 설정할 수 있다는 것과 같다. 다음과 같이 구현한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
lock = 0; // 공유 변수
entry_mutex {
key = 1; // Swap이기 때문에 1을 집어넣는 변수 공간이 필요하다
do {
Swap(&lock, &key);
} while (key == 1);
/*
언제 대기해야 할까?
기존의 Lock 값이 1일 때 대기해야 한다.
즉 Swap했는데 Key값이 1일 때 대기해야 한다.
*/
}
1
2
3
key = 1;
Swap(&lock, &key);
while (key == 1);
위 방식으로 구현하는 것과, do-while을 사용하는 것이 어떤 차이가 있을까? do-while을 하면 while 조건이 실패시 계속해서 Swap을 시도한다. 그러나 위 코드는 Swap을 딱 한번만 시도한다. 따라서 최초 한번 Swap 시도하고, key값이 변하지 않는다. 교착 상태에 걸리게 된다.
lock = 0일 때 하나의 프로세스만 entry_mutex를 실행하면? key와 lock 값을 Swap하여 key가 0, lock가 1로 설정된다. 따라서 busy waiting하지 않고 while문을 탈출한다.
lock = 1일 때 하나의 프로세스만 entry_mutex를 실행하면? key와 lock 값이 둘다 1이다. Swap해도 key == 1을 만족하여 busy waiting한다.
lock = 0일 때 여러 프로세스가 entry_mutex를 실행하면? Swap이 원소적으로 실행되어도, 멀티 코어 시스템에선 두 명령어가 동시에 실행될 수 있지 않나? 그렇다면 명령어가 원소적으로 실행되도 문제가 생기지 않을까?
실제로 멀티코어로 인해 명령어가 동시에 실행될 수 있다. 이는 문제되지 않는다. 문제가 되는 부분은, 동시에 공유 메모리에 접근하려는 시도다. 이를 해결하기 위해 메모리 동기화, 캐시 동기화를 더 깊은 하드웨어 수준에서 수행한다. 따라서 걱정하지 않아도 된다.
즉 두 프로세스가 다른 코어에서 동시에 명령어가 실행되어도, 메모리와 캐시 하드웨어 수준에서 동기화가 구현되어 있다. 따라서 lock에 접근하는 순서는 반드시 결정된다. 따라서 둘 중 하나의 프로세스가 lock = 1로 설정하여 busy waiting을 빠져나오고, 나머지 프로세스는 busy waiting 하게 된다.
(HW) compare and swap
두 값이 같으면 Swap한다. 다르면 Swap하지 않는다.
1
2
3
4
5
6
7
int compare_and_swap (int *value, int expected, int new_value)
{
int temp = *value;
if (*value == expected)
*value = new_value;
return temp;
}
만약 공유 변수가 0이면 1로 설정한다. 이후 0을 반환한다. 그렇지 않으면 1로 설정하지 않는다. 이후 1을 반환한다. 구현하면 다음과 같다.
1
2
3
4
5
6
7
8
9
lock = 0; // 공유 변수
entry_mutex {
while (compare_and_swap(&lock, 0, 1));
}
exit_mutex {
lock = 0;
}
lock = 0일 때 하나의 프로세스만 entry_mutex를 실행하면? lock과 0이 같기 때문에 lock는 1로 설정되고, 0을 반환하므로 대기하지 않는다.
lock = 1일 때 하나의 프로세스만 entry_mutex를 실행하면? lock과 0이 다르기 때문에, Swap하지 않고 1을 반환하므로 대기한다.
lock = 0일 때 여러 프로세스가 entry_mutex를 실행하면? compare_and_swap이 원소적으로 실행된다. 저 명령어 자체는 멀티코어에서 동시에 실행될 수 있지만, 메모리나 캐시 하드웨어 수준에서 동기화 되기 때문에 반드시 실행 순서가 결정된다. 따라서, 둘 중 하나의 프로세스가 lock = 1로 설정하고, 나머지 프로세스는 busy waiting한다.
lock = 1일 때 여러 프로세스가 busy waiting하다, 임계 구역에 있던 프로세스가 exit_mutex를 실행하면? lock = 0으로 변경되며, 위 문단의 상황과 동등해진다.
(HW) 인터럽트 통제
아이디어는 간단하다. Race Condition이 Context Switch에 의해 발생하는거면, 임계 구역을 실행하는 동안 Context Switch를 막아버리자!
Context Switch는 언제 실행되는가? 클락 인터럽트가 발생하거나, 다른 프로세스가 인터럽트를 발생시켜 선점하려할 때 발생할 수 있다. 즉, 임계 구역을 실행하는 동안 인터럽트를 잠시 비활성화 해두면 된다.
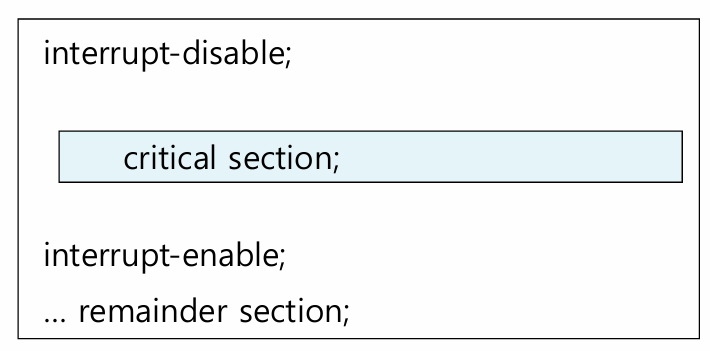
이 방법은 유저 권한으로 사용할 수 없다. 커널에서 사용할 수 있다. 또, 멀티 프로세서 시스템에선 부적합하다. 하나의 CPU의 인터럽트를 비활성화 해놔도, 다른 프로세서에서 공유 자원에 접근해버릴 수 있기 때문이다.
세마포어가 무엇인가?
Mutex는 다 busy waiting으로 구현했다. 세마포어는 blocking 상태로 전환시키는 방법이다. 진입 불가능한 프로세스는 block 상태로 전환시켜두고, 임계 구역을 떠나는 프로세스가 block 상태은 프로세스를 깨운다.
어떻게 구현하는가?
세마포어는 자원이 여러개인 상황까지 고려한다. 즉 자원을 n개 가질 수 있다. 누군가가 자원을 요청할 때마다, 하나씩 빼줘야 한다. 자원 요청 명령을 wait()라고 하자. 자원이 없으면 그 프로세스는 대기해야 한다. process block queue가 있어야 한다. 이후 자원을 다 사용한 프로세스는 자원을 반납하고, 대기 큐에 프로세스가 존재하면 가장 앞에 있는 프로세스를 깨워야 한다. 이 명령을 signal()라고 하자.
즉 세마포어란 자원 value, 대기 큐 block queue 필드와 세 메서드 init(n), wait() (P 연산), signal() (V 연산)를 갖는 객체와 같다. 특히 value의 값은 다음과 같이 해석할 수 있다.
S.value > 0: 남아있는 자원 수S.value < 0: 대기중인 대기자 수S.value = 0: 남아있는 자원과, 대기중인 대기자 수가 없음.
따라서 다음과 같이 구현한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
struct semaphore {
int value;
queue list;
}
init (semaphore* S, int n) {
S->value = n;
}
wait (semaphore* S) {
S->value--;
if (S->value < 0) {
block(); // S->list에 넣는다.
}
}
signal (semaphore* S) {
S->value++;
if (S->value <= 0) {
wakeup(); // S->list에 있는 프로세스 하나를 깨운다.
}
}
위 세 메서드는 Atomic하게 실행되어야 한다. 어떻게 Atomic하게 실행되게 할까? 세마포어를 싱글코어에서 구현한다면 인터럽트 차단 방식을 사용한다. 멀티 코어라면 인터럽트 차단 방식은 효율적이지 않다. 모든 코어의 인터럽트를 잠시 차단해야하기 때문이다. 따라서, compare & swap 또는 spinlock 방식으로 Atomic함을 보장한다.
어떻게 사용하는가?
자원 수를 여러개로 설정하면, 자원과 대기자를 관리하는 용도로 사용할 수 있다. 자원 수를 1로 설정하면 Mutex와 같이 동기화 용도로 사용 가능하다. 만약 자원 수가 0이면? 다중 쓰레드간의 순서 강제를 위해 사용할 수 있다.
다중 쓰레드간의 순서 강제가 어떻게 가능한가?
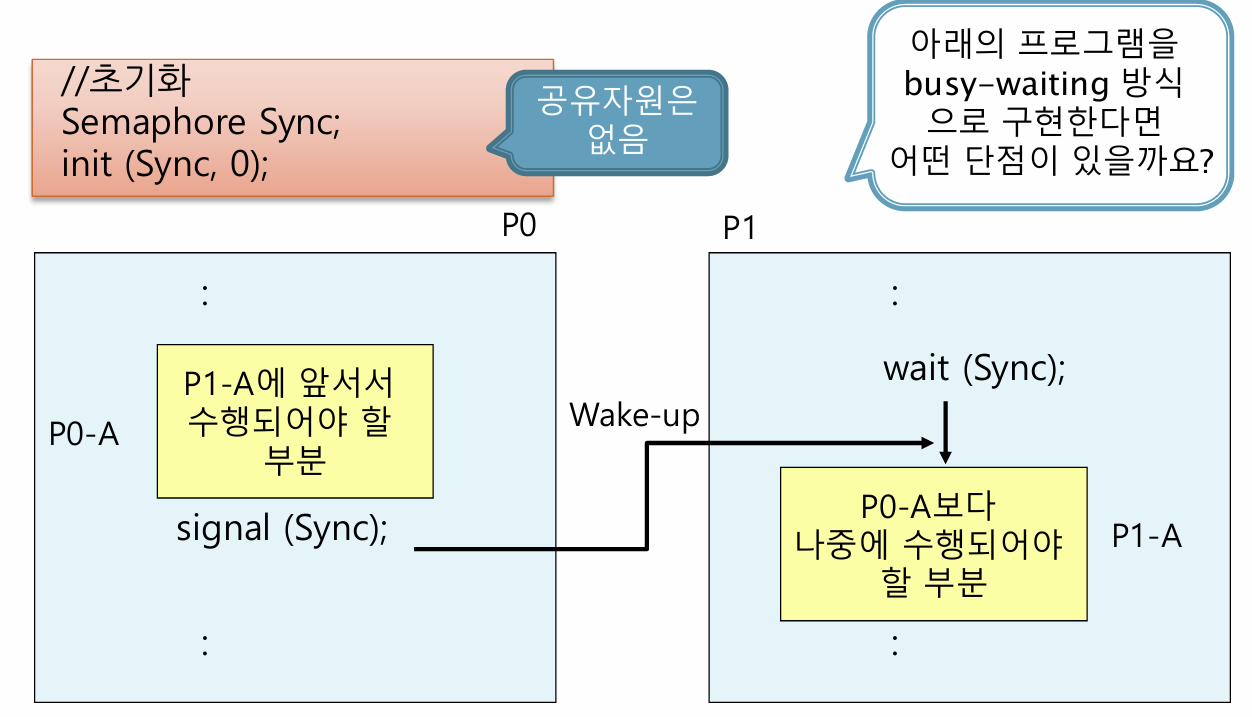
만약 P0이 P1보다 먼저 실행되어야 한다고 하자. 늦게 실행되야 하는 곳에서 세마포어를 wait()한다. 초기 자원 수가 0이었으므로, P1가 먼저 실행되면 P1은 Block된다.
그리고 먼저 실행되야 하는 부분이 실행 완료되면 세마포어를 signal()한다. P1가 Block되어 있다면, 깨어날 것이다. Block되어있지 않다면, 자원 수가 1로 증가할 것이다. 이후 P1가 실행되면 Block되지 않고 바로 실행된다.
따라서 P0 > P1 순서가 생긴다.
[!example] 생산자-소비자 문제를 세마포어로 구현{title} Producer-Consumer 문제가 무엇인가? Producer는 데이터를 생성하여 공유 버퍼에 넣는다. Consumer는 공유 버퍼에서 데이터를 꺼내어 사용한다.
이때 Producer는 버퍼가 가득 차면 데이터를 넣을 수 없다. Consumer는 버퍼가 비어있으면 데이터를 꺼낼 수 없다. 버퍼가 공유되어 있으므로, 상호 배제가 이루어져야 한다.
세마포어로 이 문제를 해결해보자. Buffer의 크기를
n이고, Item의 크기를1이라고 가정한다. 버퍼에 접근할 땐 상호 배제가 이루어져야 한다. 크기가 1인 세마포어를 하나 정의한다. 초기 버퍼는 비어있으므로 크기가 0인 세마포어도 정의한다. 그리고 데이터를 n개 넣을 수 있으므로 크기가 n인 세마포어도 정의한다. 총 3개의 세마포어를 정의한다.
Producer는
Item을 생성하고,wait(full)으로 데이터를 넣을 수 있는지 체크한다. 가능하면Item을 버퍼에 넣고,signal(empty)로 상대 컨슈머가 잠들어있으면 깨운다.
Consumer는
wait(empty)로 데이터가 있는지 체크한다. 가능하면Item을 버퍼에서 꺼낸다.signal(full)로 상대 Producer가 잠들어있으면 깨운다.
Readers-Writers Problem
하나의 공유 변수에 대해 쓰기를 할 땐, 읽기 쓰기 모두 막아야 한다. 그러나 읽을 땐, 쓰기는 막아야 하지만 읽기는 굳이 막을 필요 없다. 동시에 읽어도 문제 없기 때문이다.
write lock, read lock 두개를 만들자. write할 땐 read lock을 체크하고, 안읽고 있으면 write lock 체크해서 쓰면 된다. read할 땐, write lock을 체크하고, 안쓰고 있으면 read lock만 체크하고 쓰면 된다. 그러나 read lock이 걸려있다고 다른 프로세스가 못 읽는건 아니다.
그러나, 계속 read만 하면 write가 기아 상태가 걸릴 수 있다. 이를 위해 reader-writer 대기큐와 reader 대기큐 분리 등의 해결책이 존재한다.
우선순위 역전 문제가 무엇인가?
Mutex나 Semaphore을 사용할 때 높은 우선순위 프로세스가 낮은 우선순위 프로세스 작업이 마칠 때까지 기다려야 할 수 있다. 이는 어쩔 수 없다고 치자. 그러나, 두 프로세스의 우선순위의 중간 우선순위를 가진 프로세스가 실행되면 우선순위 역전 문제가 발생한다.
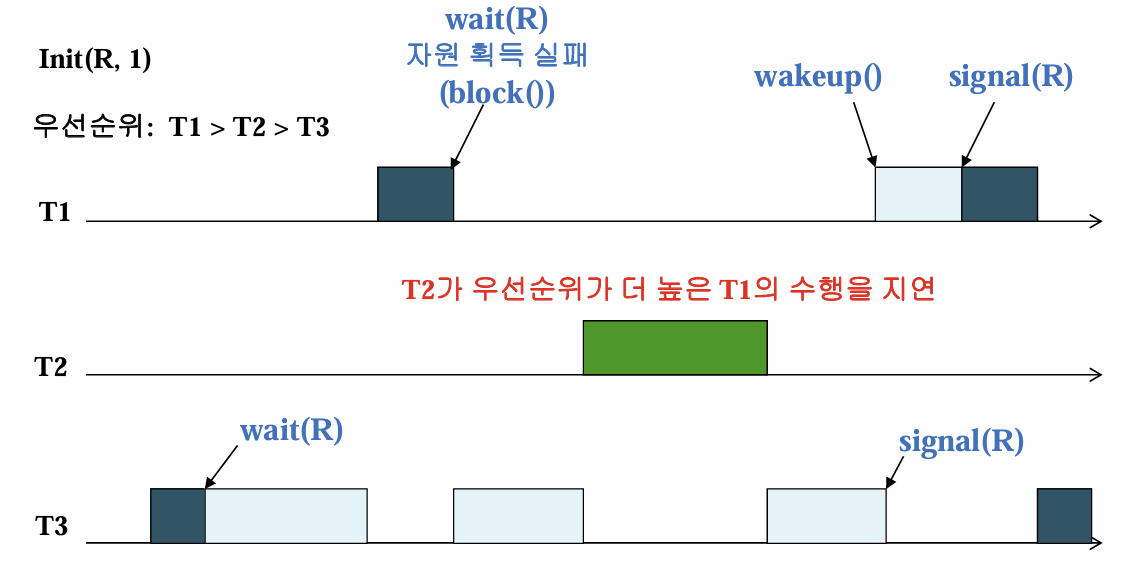
T1은 T3이 자원을 뱉을 때까지 기다리고 있는데, T3보다 우선순위가 높고, T1보다는 낮은 T2가 CPU를 선점해서 작업을 먼저 처리해버린다. 결과적으로 T2가 T1보다 더 먼저 실행되는 우선순위 역전이 발생한다.
이를 어떻게 해결하는가? 자원을 뺏을 순 없다. 다만 우선순위가 낮은 애가 작업을 후딱 끝낼 수 있게 우선순위를 높여줄 순 있다. 따라서, T3의 우선순위를 T1으로 잠시 격상한다.
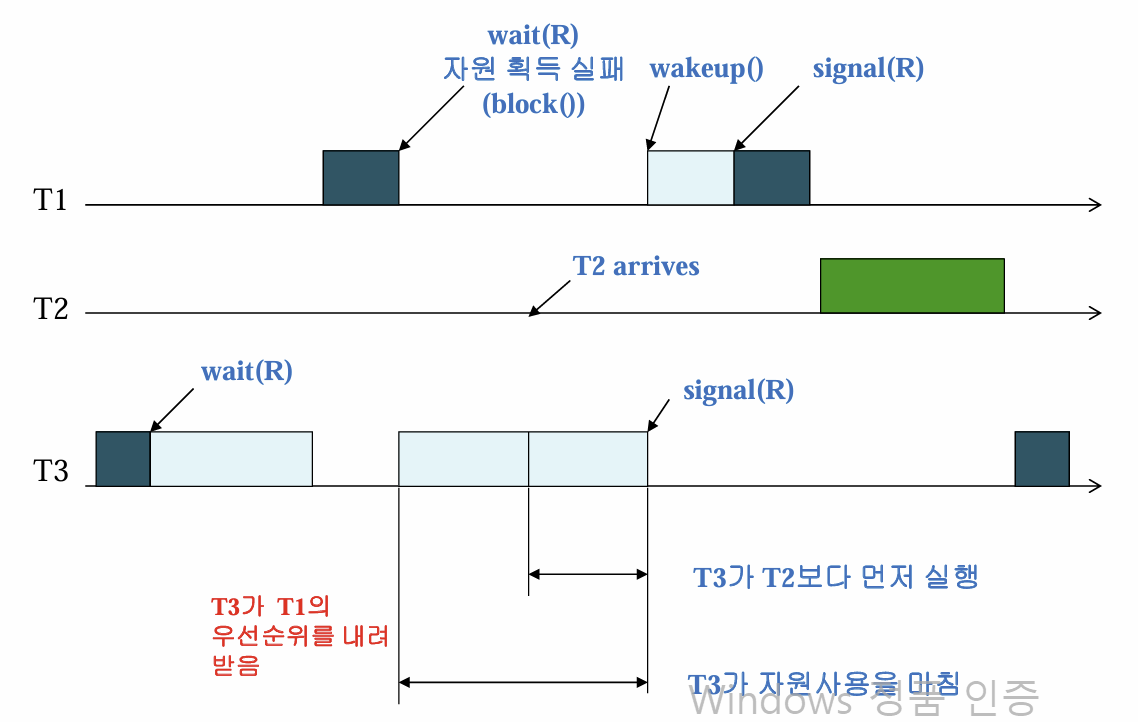
그러면 T2가 T3의 작업을 선점할 수 없기 때문에 T3가 후딱 작업을 끝낼 수 있다. 그러면 T1이 T2보다 더 빨리 실행되게 된다. 이 방법을 우선순위 상속 프로토콜(Basic Priority Inheritance(BPI) Protocal) 이라고 한다.