운영체제 10. Process, Context, PCB
프로세스는 무엇인가?
프로세스란 한마디로 실행 중인 프로그램이다. 프로그램은 저장장치에 들어있는 기계어 덩어리고, 프로세스는 메인 메모리 위에서 CPU에 의해 실행되고 있는 기계어 덩어리다.
여러개의 프로세스를 관리할 수 있는 시스템을 멀티 태스킹이 가능한 시스템이라 한다. 태스크란 프로세스와 같다. 적어도 운영체제에선 태스크와 프로세스를 구분하지 않는다.
프로세스란 운영체제 입장에서 자원을 요구하는 주체다. 프로세스는 크게 유저가 만든 사용자 프로세스와, 커널이 만든 시스템 프로세스 두가지가 존재한다. 시스템 프로세스가 사용자 프로세스보다 우선일까? 그렇지 않다. 자원 경쟁은 동등한 조건에서 벌어진다.
어떻게 여러 프로세스를 동시에 실행할까?
정확히는 동시에 실행하는 것 처럼 보이게 한다. 빠른 시간동안 프로세스를 번갈아가면서 실행한다. 그것이 가능하기 위해선, 기존의 실행하던 프로세스의 상태를 그대로 백업해 뒀다가 다시 그 프로세스를 실행할 때 이전 상태에서 이어서 실행해야 한다. 프로세스의 상태를 Context라고 하고, Context를 교체하는 작업을 Context Switch라고 한다. Context를 담는 자료구조는 Process Control Block (PCB) 라고 부른다.
어떤걸 Context로 저장해야 할까?
Context는 크게 User-level context와 Kernel-level context로 구분한다.
- User-level Context
- Text
- Data
- Stack
- Kernel-level Context
- 특수 Registers
- Program Counter (PC)
- Stack Pointer (SP)
- Program State Regster (PSR)
- 범용 Registers
- 자원 사용 정보
(Open한 File, heap 메모리 등...) - Process 정보
(실행된 시간, Time Slice 등...)
- 특수 Registers
이 모든 내용은 PCB 자료구조에 저장되어 커널에게 관리된다.
사용자 수준 Context가 무엇인가?
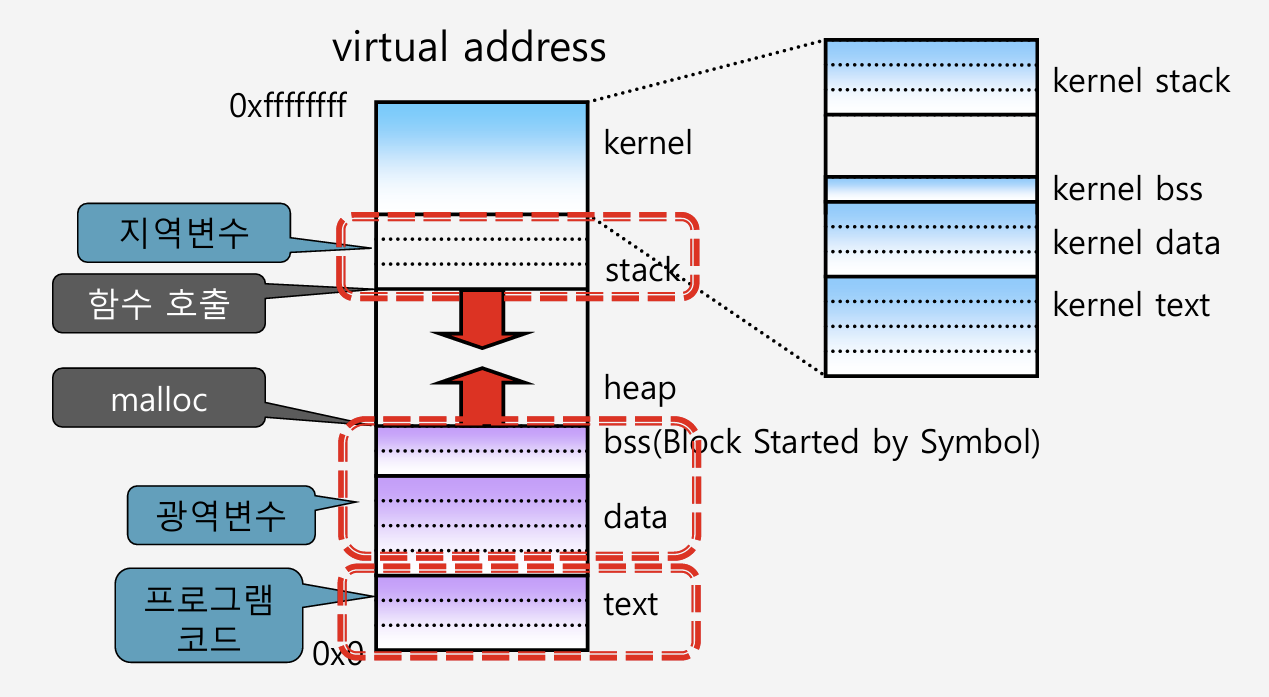
User-level Context는 어떤 정보를 갖는가? 크게 Text, Data, Stack으로 구분한다. Text 영역은 프로그램 코드를 의미한다. Stack 영역에는 지역 변수, 함수 파라미터 변수, 함수 콜백 주소 등이 저장된다. Data 영역은 광역 변수를 의미한다. 초기화가 된 광역 변수는 data, 초기화가 되지 않은 광역 변수는 bss로 구분한다.
bss가 무엇인가?
왜 data와 bss의 영역을 따로 만들어서 구분하는가? 메모리 효율 때문이다. 예를들어 다음과 같은 광역 변수를 선언했다고 가정하자.
1
2
char arr1[1024];
int arr2[8] = {1, 2, 3, 4, 5, 6, 7, 8};
arr2의 경우는 초기화가 되있고, arr1은 초기화가 안된다. arr2는 코드에 초기화한 값이 직접 들어 있으므로, 컴파일 할 때 바이너리 코드에 들어가야 한다. 그러나 arr1는 어차피 값도 없기 때문에, 굳이 미리 0으로 초기화된 값을 저장해둘 필요가 없다. 배열의 크기만 바이너리 코드에 들어가도 무방하다.
추후 프로그램이 실행되면서 프로세스로 만들어질 때, 초기화된 광역변수는 data 영역에 잡아 초기화까지 한다. 초기화되지 않은 광역변수는 bss영역에 잡아 크기만 할당하면 된다.
커널 수준 Context가 무엇인가?
Kernel-level context는 어떤 정보를 갖는가? CPU 수준의 레지스터(PC, SP, PSR, 범용 레지스터)는 반드시 저장되어야 한다. 그러나 각종 자원 사용 정보나 프로세스의 실행 시간 등이 저장되어야 하는 이유는 무엇인가?
(1) 각종 자원 사용 정보 만약 프로세스가 예기치 못하게 갑자기 죽으면, 커널은 죽은 프로세스가 할당해뒀던 자원을 해제해야 한다. 만약 이 정보를 PCB가 담고있지 않으면, 알 수가 없다. 자원을 해제하지 못하면 낭비로 이어진다. 따라서 PCB에 파일 오픈과 같은 정보를 저장해둔다.
(2) 실행 시간 등의 프로세스 정보 이 정보는 스케쥴링, 우선순위 책정 등에서 사용된다. 추후 스케쥴링 항목에서 자세히 다루겠다.
Stack Pointer가 무엇인가?
User-level Context의 Stack 영역의 Top을 가리키는 주소와 같다. 그 주소는 실제 메모리의 주소인가? Virtual Address인가? Virtual Address이다. CPU에서 Virtual Address를 받으면, MMU에게 가상 주소를 넘겨 실제 메모리 주소로 변환할수 있다.
Program State Register가 무엇인가?
PSR에는 연산의 상태를 저장한다. 상태는 다음과 같다.
- Zero Flag : 연산 결과가 0인지 여부
- Carry Flag : 덧셈 연산 결과로 캐리 발생 여부 (자리 올림, 내림)
- Sign Flag : 연산 결과가 음수인지 여부
- Overflow Flag : 연산 결과가 표현 범위를 초과했는지 여부
- Parity Flag : 1비트 개수가 짝수인지 홀수인지 여부
- Interrupt Enable Flag : 인터럽트를 받을지 안받을지의 여부. 0으로 설정되어있다면 모든 마스크 가능한 하드웨어 인터럽트를 무시한다. 중요한 인터럽트는 무시하지 못한다.
이런 상태를 저장하는 이유가 무엇인가? 숫자를 표현하는 크기에 한계가 있기 때문이다. 두 숫자를 더했는데 캐리와 오버플로우가 동시에 발생했다. 만약 다음 연산에서 오버플로우를 고려하지 않는다면 큰 단위의 숫자가 그대로 손실된다. 따라서 CPU는 연산하기 전에 이전 연산의 상태를 고려하여 적절한 연산을 수행할 수 있다.
또, 어셈블리에서 Condition Codes로서 비교판정을 구현할 수 있게 해준다. 예를 들어 비교하고 싶은 두 값을 뺀 뒤에 Sign Flag와 Zero Flag를 체크하여 어떤 값이 더 큰지, 같은지 판단할 수 있다.
범용 레지스터의 용도가 무엇인가?
범용 레지스터는 보통 효율성을 위해 연산에서 자주 쓰이는 데이터를 메모리 대신에 저장하는 공간이다. 다음과 같은 용도로 사용된다.
- 어셈블리 프로그래머가 작업 공간으로 사용할 수 있음
- CPU는 연산 효율을 위해 메모리에서 범용 레지스로 데이터를 가져온다.
- 기존의 연산 결과를 재활용 할 때 범용 레지스터에 담아둠. 매 연산할 때마다 메모리에 저장했다가 다시 불러오면 Bus 연산이 자주 발생해 효율이 낮아지기 때문.
레지스터가 어떻게 사용되는지 CPU 동작 수준에서 살펴보자.
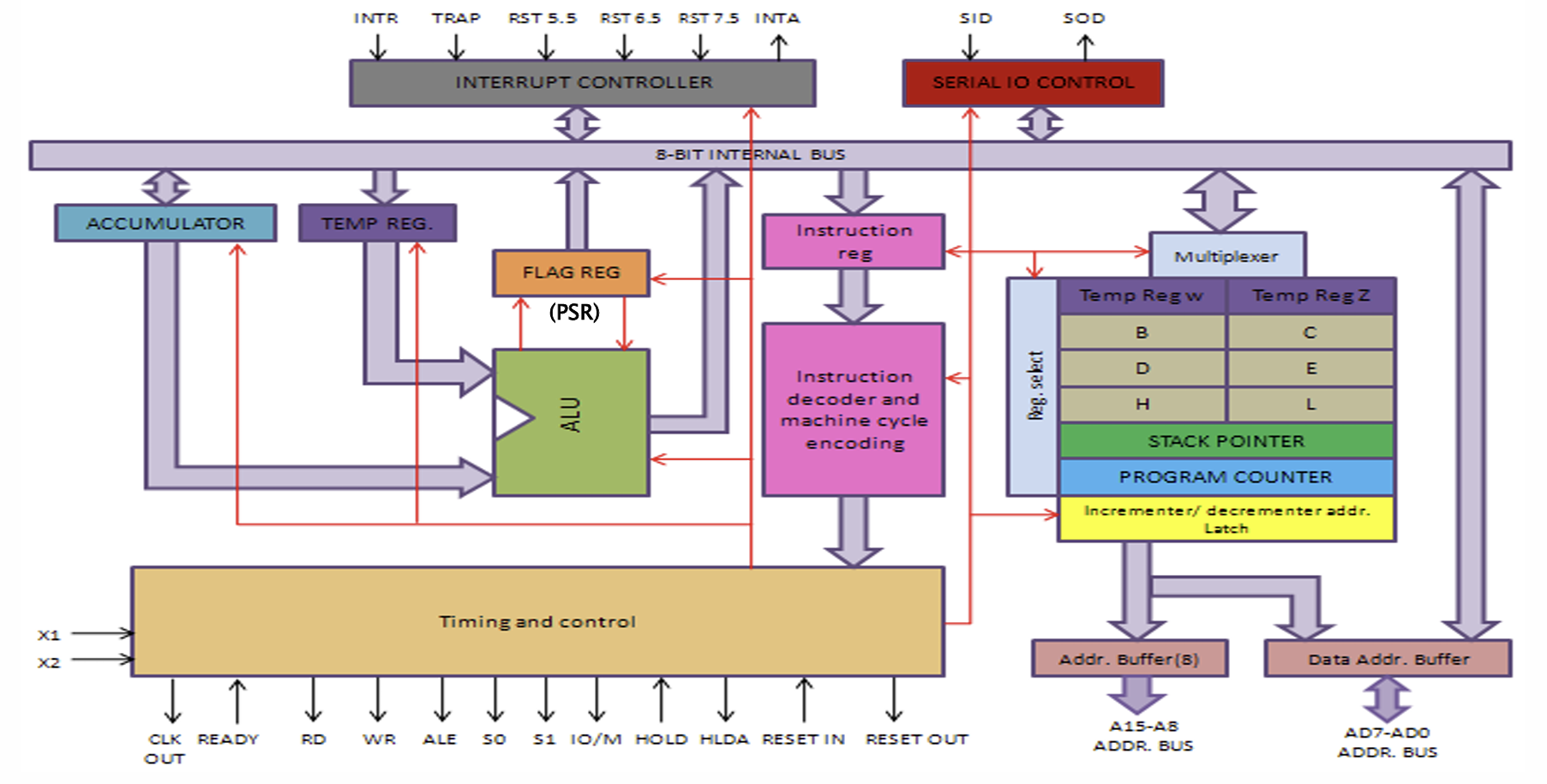
CPU는 단순히 Fetch, Decode, Execute 싸이클만 무한 반복하는 빡대가리 하드웨어와 같다. CPU의 제어 장치(CU)는 가장 먼저 Program Counter 레지스터에 접근해서 실행할 명령어가 담긴 가상 메모리 주소를 얻는다. 이후 PC 값을 1 늘린다.
가져온 가상 메모리 주소를 Address Register에 저장한다. Address Register에 저장된 가상 주소는 MMU에게 전달되어 실제 메모리 주소로 변환된다. 변환된 메모리 주소는 Address Bus를 타고 Memory에게 전달된다.
메모리는 Address Bus를 타고 들어온 주소를 보고 Data를 읽어 Data Bus를 통해 데이터를 보내준다. CPU는 Data bus를 통해 받은 데이터를 IR (Insturction Register)에 저장한다. 여기까지가 Fetch 과정이다.
Insturction Register에 저장된 데이터는 제어 장치가 해독한다. 해독하면 CPU 수준에서 어떤 명령어인지 알 수 있게 된다. 해독한 명령어에 따라 다른 작업을 수행한다.
- 계산해야 하면 Control에다 집어넣음. Control에선 ALU와 여러 레지스터를 사용해 연산함.
- 레지스터에다 저장해야 하면 레지스터에 쓰기 신호를 보냄.
- 메모리를 읽거나 써야한다면 다시 Address Bus를 이용함.
ALU를 통해 연산을 수행하면 두가지 결과가 생긴다. 하나는 연산 결과다. 이 연산 결과는 대부분 int c = 2+3;과 같이 어떤 변수에 저장된다. 변수에 저장된다는 뜻은 그 변수에 해당하는 메모리 주소에 데이터를 저장해야 함과 동일하다. 따라서 Address Buffer와 Data Buffer와 명령 Buffer에 각각 저장할 메모리 주소, 연산 결과, Write를 적어서 보내면 메모리에서 이를 받고 해당 메모리 주소에 데이터를 저장한다. 두번째는 연산 상태 데이터다. 이 연산 상태 데이터는 CPU의 PSR에 저장되어 다음 연산에서 사용된다.
Context Switch는 언제, 누가 수행하는가?
커널이 누군가에 의해 호출되면 밀려있던 스케쥴링 작업을 수행한다. 이때 Context switch가 일어날 수 있다. 커널이 호출된다는 것은 Clock instrrupt가 발생하거나, 트랩을 거는 상황을 말한다.
Context Switch는 다음 네가지 케이스에서 수행된다.
- 프로세스의 Time Slice가 다 되었을 때
- 우선순위가 더 높은 인터럽트가 발생했을 때
- I/O를 수행해서 CPU를 자발적으로 반납할 때
- 시그널 등이 들어올 때까지 자발적으로 대기상태로 전환할 때
1, 2번은 비자발적 문맥 교환, 3, 4번은 자발적 문맥교환으로 구분한다. 비자발적 문맥 교환은 항상 Run 상태에서 Ready 상태로 전환되고, 자발적 문맥교환은 Run 상태에서 Blocked 상태로 전환되는 특징이 있다.
프로세스는 어떤 상태가 있는가?
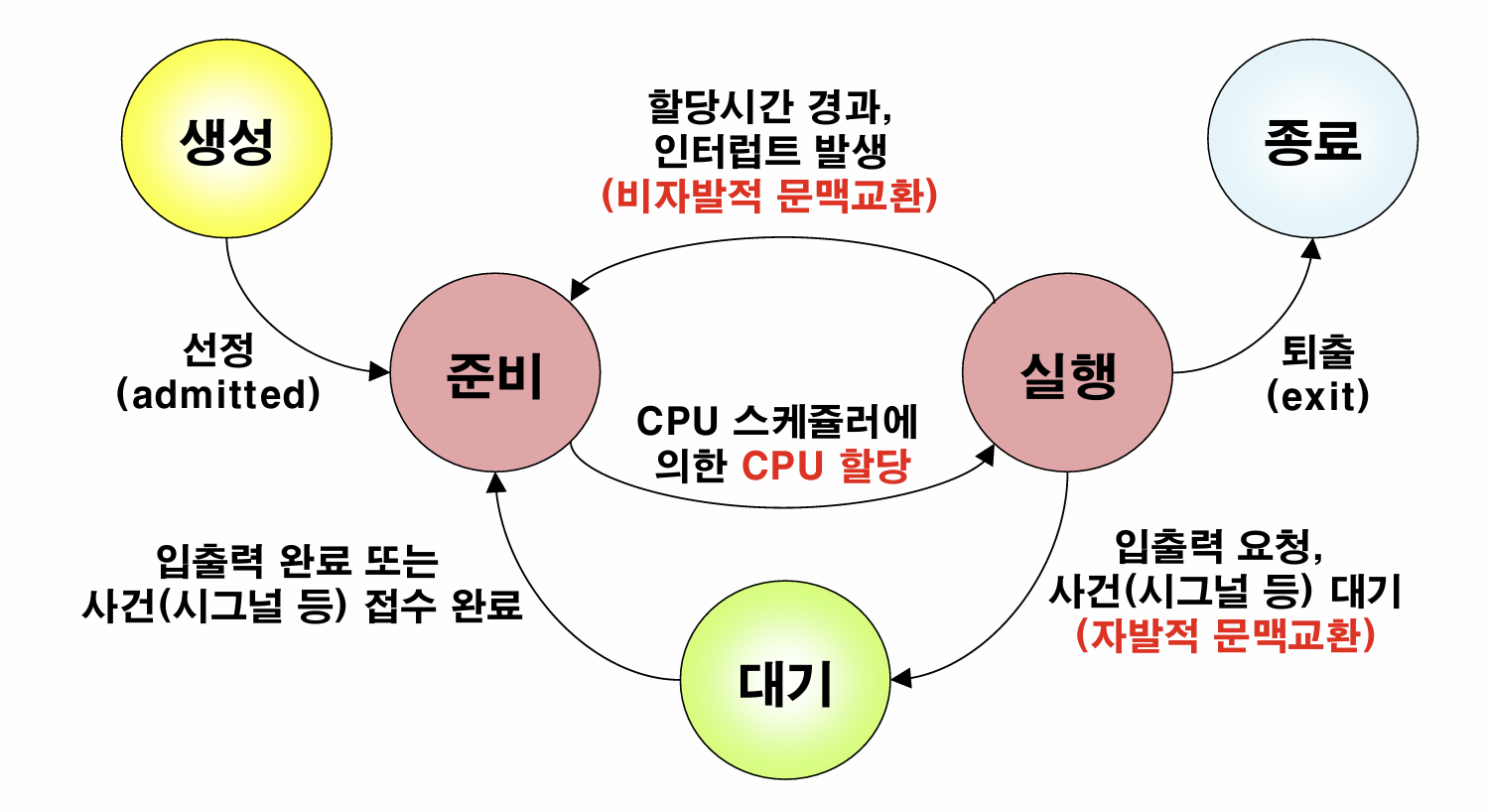
총 다섯가지 상태가 존재한다.
- 생성 상태 : 프로세스가 막 생성된 단계. 커널은 생성 상태에 있는 프로세스의 초기화를 담당한다.
- 준비 상태 : CPU가 할당될 때까지 준비중인 상태
- 대기 상태 : 누군가 해제해 줄 때까지 CPU 할당을 안받겠다고 선언한 상태
- 실행 상태 : CPU 자원을 할당받은 상태
- 종료 상태 : 프로세스가 종료된 상태. 커널은 종료 상태에 있는 프로세스의 리소스 종료를 담당한다.
상태 정보는 PCB에 기록된다. 준비 상태에 있는 프로세스는 모두 Ready Queue에 들어있다. Ready Queue는 우선 순위에 따라 정렬된 상태와 같다. 스케쥴러는 Context Switch할 때 Ready Queue 맨 앞에 있는 프로세스를 골라 실행 상태로 전환한다. 이때 따로 Run Queue같은게 있는 건 아니고, 그냥 준비 상태에 그대로 냅둔다.
대기 상태도 여러개의 Blocking List에 들어간다. Ready, Blocking Queue의 실체는 PCB 포인터를 저장하는 리스트다. 커널 입장에서 프로세스 = PCB와 같다.
준비 상태는 Inbound가 3개, Outbound가 1개다.
- Inbound
- 생성 상태 -> 준비 상태
- 대기상태 -> 준비 상태
- 실행 상태 -> 준비 상태.
- Outbound
- 준비 상태 -> 실행 상태.
실행 상태는 Inbound가 1개, Outbound가 3개다.
- Inbound
- 준비 상태 -> 실행 상태.
- Outbound
- 실행 상태 -> 종료 상태
- 실행 상태 -> 대기 상태
(자발적 문맥교환) - 실행 상태 -> 준비 상태
(비자발적 문맥교환)
PCB엔 어떤 정보가 들어가는가?
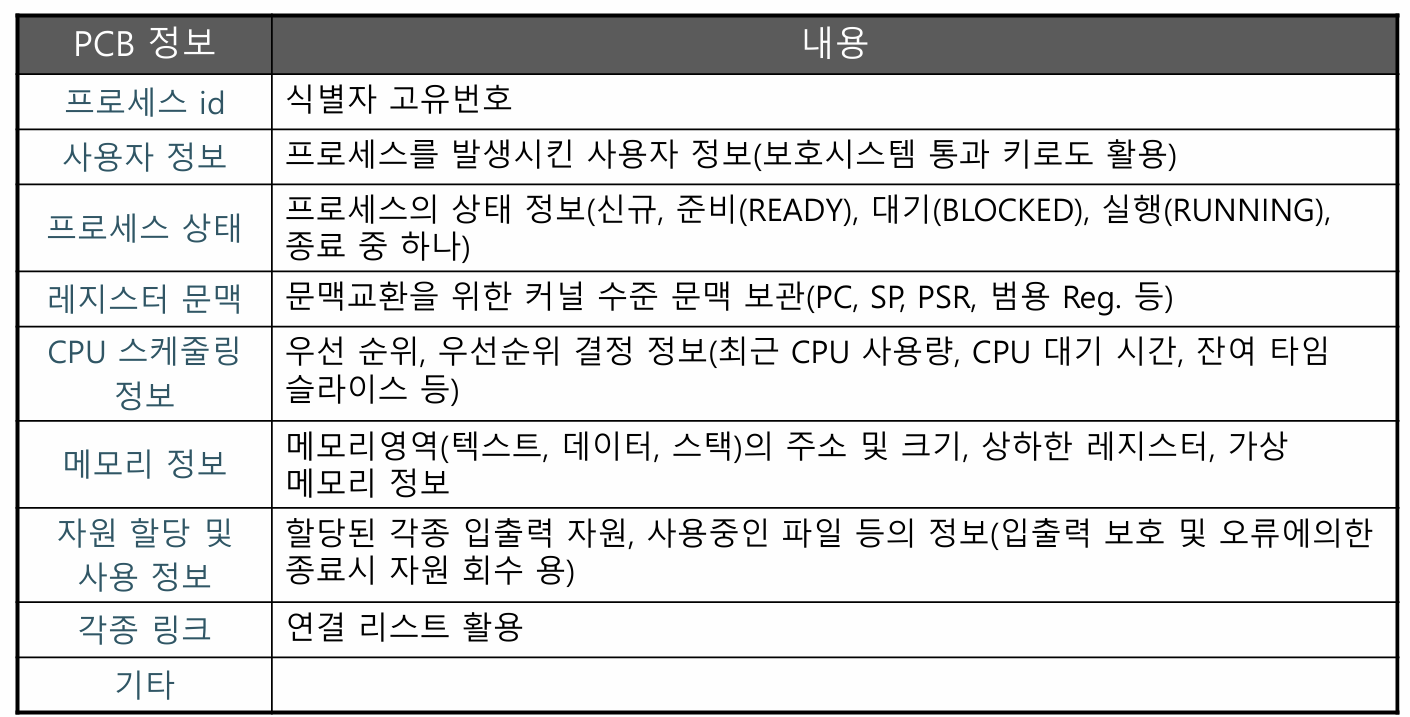
PCB는 프로세스 부모 관계에 따라 Double Linked List로 연결된다. Double Linked List인 이유는 Search 속도를 높히기 위함이다.
프로세스가 종료 상태가 되면 어떤 일이 벌어지나?
프로세스가 종료되는 케이스는 두가지가 있다. exit() 호출로 인해 스스로 종료되는 경우, abort()를 사용하여 부모 프로세스가 자식 프로세스를 종료시키는 경우. 아무튼 프로세스가 종료하면 자식 프로세스의 주소 공간과 할당된 자원은 해제된다. 하지만 exit code를 부모에게 넘겨 주어야 한다. 다른건 다 할당 해제되는데 이 exit code는 어디에 담아야 하냐? PCB밖에 없다. 따라서 프로세스는 종료했지만 PCB는 남아있는 아이러니한 상태가 바로 종료 상태와 같다. 부모 프로세스가 자식 프로세스 중 종료 상태가 된 프로세스를 reaping하면 그 과정에서 PCB를 제거하면서 종료 코드를 부모 프로세스가 알 수 있게 된다. 만약 reaping 과정이 없다면 자식 프로세스의 PCB는 계속 남아있게 된다. 이를 좀비 상태라고 부른다.
프로세스는 어떻게 생성되는가?
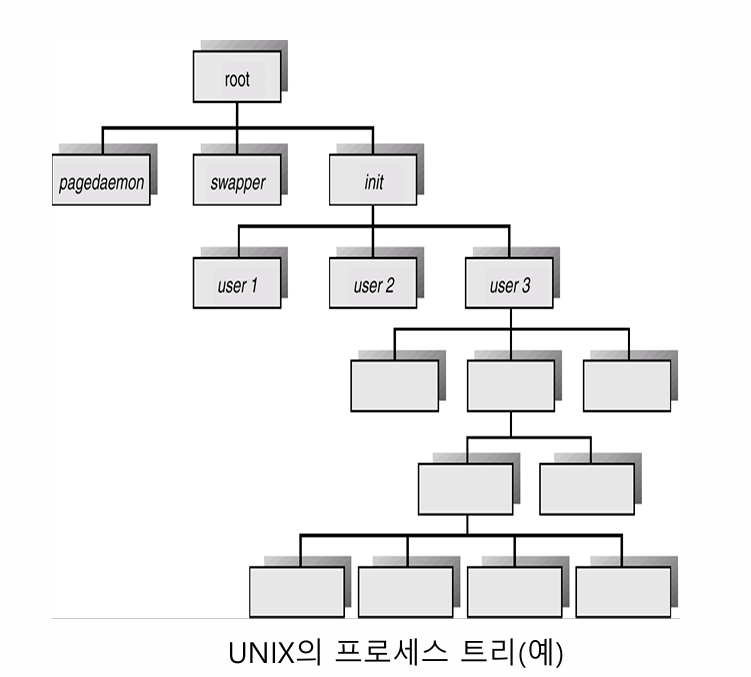
태초의 프로세스를 생성하고, 그것을 fork()하면서 프로세스를 만든다.
fork()가 호출되면 운영체제 내에서 어떤 일이 일어날까?
fork()를 실행하면 부모 프로세스의 모든 것을 복제하여 자식 프로세스를 생성하고, 복제된 다음 순간부터 자식 프로세스는 실행된다. 따라서 fork()의 리턴값은 부모 프로세스에선 자식 프로세스의 PID 값을, 자식 프로세스에선 0을 반환한다. 운영체제 내에선 어떤 일이 벌어질까?
[!question] 어 근데 프로그램 카운터는 똑같이 복제하면 안되지 않나?{title} 왜냐면 프로세스를 통쨰로 복제하면 그 코드는 다른곳에 이동할 거니까. => 그렇지 않다. text 영역은 어차피 부모나 자식이나 코드는 바뀌지 않기 떄문에 복제할 필요가 없다. 따라서 text 영역은 서로 공유하고, 나머지 data, stack heap 영역과 같은 곳은 복제해서 따로 관리한다.
fork()를 만들면 자식 프로세스를 생성한다. 프로세스를 생성한다는 것은 PCB를 만드는 것과 동등하다. 이때 PCB의 값은 부모 프로세스의 모든 것을 복제한다. 딱 하나 굳이 복제하지 않아도 되는 text 영역은 부모 프로세스의 메모리 주소를 참조하는 방법을 사용한다.
부모 프로세스의 코드를 사용하지 않고 새로운 코드를 메모리에 올리는 자식 프로세스를 만들 수 있을까?
fork + exec를 사용하면 된다. 새로운 코드는 어디에 들어있을까? 하드디스크에 들어있다. 따라서 exec는 디스크에서 프로그램을 불러와 메모리에 새로운 프로세스를 적재시키는 함수다.
exec는 코드 부분만 새롭게 하고 다른 PCB 영역은 건들지 않는건가? 그렇다. PID와 부모 자식 관계 등은 유지하면서 딱 바꿔야 할 부분 (text, data, stack 영역)만 교체한다.
exec를 실행하면 어떤 일이 벌어지는가?
PCB를 새로 만든다. 위에서 설명했듯이, PID나 부모 자식 관계 등은 기존의 정보를 물려받고, 그렇지 않은 부분은 새로은 프로그램 정보로 초기화한다. fork()와 가장 큰 차이점은 text 영역이 부모 프로세스의 영역을 참조하는 것이 아닌, 새로운 text 영역을 할당받는 다는 것이다. 따라서 PC도 text 영역의 첫번째 주소로 이동해야 한다.
모든 Shell 프로그램은 fork + exec를 사용하여 명령어를 실행시킨다. 사실 Shell의 모든 명령어들 하나하나가 다 프로그램이다. 예를들어 ls 명령어를 입력하면 ls 프로그램이 fork + exec를 통해 실행된다. 프로그램이 Forward인지 Background에 따라 Shell이 Wait 상태로 전환될지 안될지 차이점이 있다. ls는 Forward이므로, Shell이 wait() 함수를 사용하여 자식 프로세스가 종료될때까지 reaping을 대기한다. ls가 종료되면 ls 프로세스를 reaping하면서 shell이 다음 명령어를 칠 수 있는 상태가 된다.
명령어는 사실 fork와 exec로 실행하고 명령어 하나하나가 하나의 프로세스를 실행하는 거였음! window에서 더블클릭 하는것도 fork와 exec가 일어나는 것이다.
Context Switch 기준으로 Read() 시스템 콜 호출 과정을 살펴보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
int main()
{
int fd;
char buf[100];
/* do something… */
n = read (fd, buf, 100); // 사용자모드에서 실행 중
// 시스템 호출을 하여 커널로 진입하여
// 커널 모드 실행.
// 복귀 시는 다시 사용자 모드로 복귀
/* do something… */
}
프로세스가 fork + exec 명령어를 통해 생성되었다. 프로세스가 생성되었다는 것은 PCB가 생성된 후 ready queue에 적재됨과 동일하다. 스케쥴링하여 실행 상태로 전환되어야 main 첫번째 줄이 실행되기 시작한다.
호출된 두 변수는 data 영역에 할당된다. 이후 read 함수를 살펴보자. read를 호출하면 libc.a 라이브러리 내의 read 함수를 호출한 것과 같다. 그 read 함수 내엔 트랩 거는 명령어가 존재한다. 트랩을 걸면, CPU에서 인터럽트 처리 루틴이 실행된다. 인터럽트 처리 루틴은 커널 모드로 전환 후 Interrupt Handler 함수로 이동하여 Context를 보존 후 두개의 테이블을 거쳐 실제 sys_read()로 이동한다.
이때 의문점. Interrupt Handler에서 Context를 보존하는 것도 Context Switch의 일종인가? 그렇지 않다. CPU를 다른 프로세스에 넘기는 것이 아니다. 따라서 이 과정은 문맥 교환이라 보지 않는다.
1
2
3
4
5
6
7
8
int sys_read()
{
// file offset을 실제 disk block number로 변환한다.
// disk i/o 요청 블록을 생성하여, disk i/o Queue에 입력한다.
// queue의 순서가 다 되면 디바이스 컨트롤러에 I/O 명령을 내린다.
// Sleep_on (디스크 입출력 완료)
// 사용자 모드로 복귀한다. 이때 스케쥴링을 할건지, 기존의 작업을 계속 이어서 할건지는 운영체제마다 다르다.
}
disk block number를 얻고, 만약 disk cache에 disk block number가 존재하면 거기서 원하는 정보를 뽑아 sys_read() 함수의 반환값으로 종료한다.
캐쉬에 없다면 Disk를 직접 읽어야 한다. 디바이스 드라이버 함수 중 read 함수에 접근한다. disk_intr_handler() 디스크 I/O 요청 블록을 생성하고, 디스크 I/O Queue에 넣는다. 이렇게 하는 이유는, 디스크 또한 동시에 접근할 수 없으므로 큐를 통해 순차적으로 작업을 처리하기 위함이다. Queue 순서가 되면, 디스크 컨트롤러의 명령 레지스터에 read 명령을 넣는다. 이후 할게 없으므로 자발적으로 CPU를 반환한다. sleep_on()
1
2
3
4
5
6
7
8
9
10
11
12
13
int sleep_on(event_name)
{
// 현재 프로세스의 PCB 상태를 BLOCKED로 변경함.
// 준비 리스트에서 현 프로세스의 PCB를 삭제함.
// 현 프로세스의 PCB를 event_name Block Queue에 삽입함.
// 준비 리스트에서 우선순위가 가장 높은 PCB를 선정한다.
// 선정된 프로세스의 상태를 RUNNING으로 바꾼다.
context_Switch (old_PCB, new_PCB); // 컨텍스트 스위치가 수행되면 더이상 밑 줄이 다시 스케쥴링 되기 전까지 실행되지 않는다.
// 이부분이 실행된다는 것은 프로세스가 ISR에 의해 READY 상태로 변환되어 디시 스케쥴링되었다는 것과 같다.
return;
}
언제 sleep가 깨어나는가? 디바이스가 I/O를 끝내면 CPU에게 인터럽트를 건다. 인터럽트를 받으면 ISR이 실행되면서 대기 상태였던 프로세스를 준비 상태로 옮기고 스케쥴링을 수행한다.
이후 다시 스케쥴링되면 sleep_on() 함수가 리턴된다. 함수가 리턴되면 disk_intr_handler() 함수의 다음 줄에서 자료 레지스터의 값을 메인 메모리 (사용자 영역)으로 복사한다. 이 과정에서 자료 레지스터에 직접 접근하거나 메모리 mapped 방법 중 하나를 사용할 수 있다. 하드웨어 여건에 맞춰 CPU가 직접 데이터를 가져오는 명령을 수행할 수도 있고, DMA를 사용할 수도 있다. 이는 Device Driver의 구현에 따라 다르다. 이후 반환하면 sys_read() 함수로 복귀한다. read 과정이 모두 완료되었으므로 사용자 모드로 전환 후 복귀하거나, 스케쥴링한다.