가상현실 5. 청각으로 어떻게 정보를 받아들일까
청각
소리를 어떻게 들을 수 있을까?
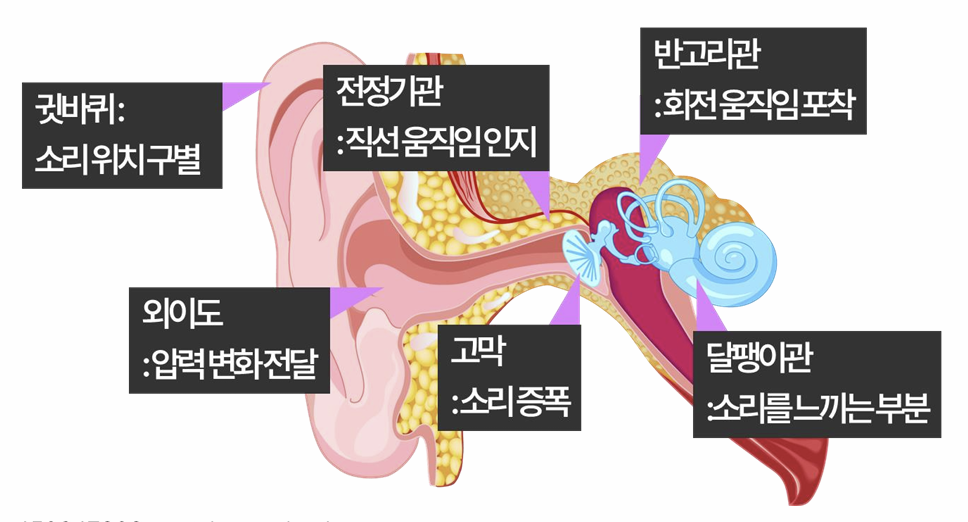
소리는 매질에 매개되어 종파로써 귀에 들어온다. 종파로 들어온 소리는 귓바퀴·외이도를 거쳐 고막으로 전달된다. 파동에 의해 고막이 진동하며, 달팽이관을 건들게 된다. 달팽이관 내의 액체가 흔들리게 되며, 떨림에 정도에 따라 달팽이관 중심부의 청각 세포가 반응하여 전기 신호로 변환한다.
소리의 속성
Frequency와 Amplitude 속성이 있다. 높은 Frequency는 높은 음, 낮은 Frequency는 낮은 음이다. 높은 Amplitude는 큰 소리, 낮은 Amplitude는 작은 소리로 지각된다.
소리를 지각하는 정보
음량(Loudness)는 진폭을 바탕으로 느끼는 소리의 크기다. 음의 높이(Pitch)는 주파수를 바탕으로 느끼는 소리의 높낮이다. 음색(Timbre)는 여러 harmonic이 조화롭게 섞였을 떄 좋다고 느낀다.
청각 역치 (Auditory Threshold)
사람은 20~22000Hz 범위를 듣는다. 2000~4000Hz 대역에 민감한데, 이 대역은 말을 이해하는데 가장 중요하다.
거리감을 어떻게 느끼는걸까?
거리감을 느끼기 위한 두가지 중요한 단서(Cues)가 있다.
(1) Binaural Cues 양쪽 귀를 비교해서 느낄 수 있다. 두가지 요소를 둘다 사용해서 거리감의 차이를 느낀다. 첫번째로, 소리가 두 귀에 도달하는 시간 차이를 이용하는 것이다. 이를 ITD(Interaural Time Difference)라 한다. 더 가까운 쪽이 소리가 먼저 들리게 된다. 귀는 이 차이를 미세하게 감지할 수 있다.
두번째로, 두 귀의 음량 차이를 느낀다. 이를 ILD(Interaural Level Difference)라 한다. 더 가까운 쪽이 소리가 더 크게 들린다.
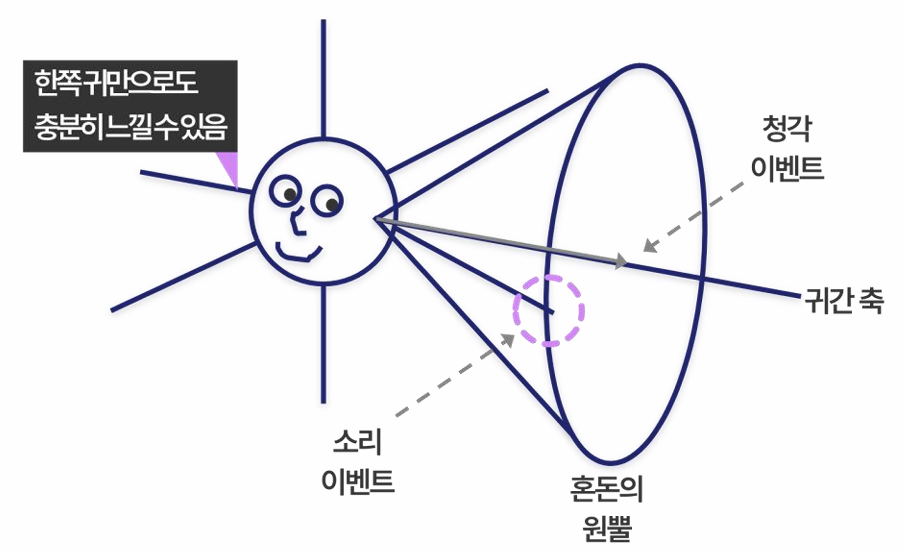
(2) Monaural Cues 한쪽 귀만으로 판단하는 공간 정보. 한쪽 귀에서 인지할 수 있는 공간은 원뿔 범위인데, 대충 어디있는지 감지할 수 있다. 바로 귓바퀴에서 고막으로 가는 반사 패턴이 위치에 따라 다르기 때문이다.
말을 어떻게 인지하는걸까? (Speech Recognition)
문장은 여러 구문phrase의 집합이고, 구문은 여러 단어word의 집합이고, 단어는 형태소morpheme의 집합이고, 형태소는 여러 음절phoneme의 집합이다.
- 음절: ‘ㅂ’, ‘ㅏ’
- 형태소: ‘바’, ‘사’
- 단어: ‘바보’, ‘사과’
- 구문: ‘나는’, ‘사과를’
- 문장: ‘나는 사과를 먹었다’
뇌는 주파수·진폭·음색을 분석하여 개별 음절에 대응하는 음향 패턴을 식별한다.
따라서 Phoneme의 인지력이 높을 수록 많은 소리를 들을 수 있다. 낮을 수록 많은 소리를 들을 수 없다. 특정 발음을 못하는 이유는, 유년기에 해당 음절을 듣지 못했기 때문에 뇌에서 구분할 수 없기 때문이다.
이후 Phoneme를 결합해 Morpheme를 인지한다. 이후 단어로, 이후 문장으로 인지한다.
청각 몰입감을 높이는 추가적인 정보들
두가지 Cue 외에 Additional한 Cues가 존재한다.
(1) Shoulder Response 소리가 우리 어깨·몸통에 반사되어 되돌아오는 소리도 존재한다. 이것이 없다면 ‘공간에 붕 떠있는’ 부자연스러운 느낌을 받을 수 있다.
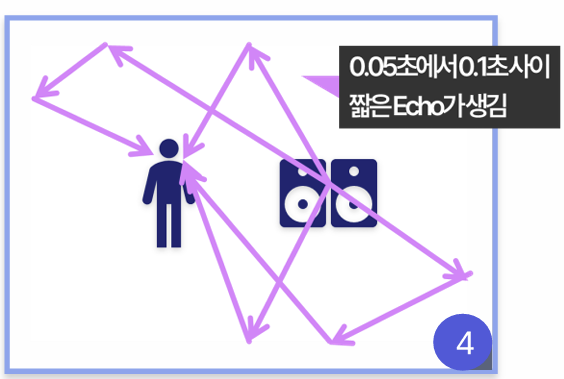
(2) Early Echo Response 소리가 공간에 부딪히면 짧은 Echo 반사파가 생긴다. 이것은 공간의 크기나 형태를 인지하는데 중요하다.
(3) Reverberation 더 늦게, 여러차례 반사되어 들리는 잔향. 공간감과 거리감을 강화한다.
(4) Head Motion 머리를 움직이면 ILD·ITD와 주파수 성분이 미세하게 동적으로 변한다.
(5) Visual Information 시각과 청각 자극이 불일치하면, 뇌는 시각을 우선시한다. 따라서 Binding이 안되면 청각이 무시될 수 있다.
소리를 가상 세계에서 어떻게게 Simulation할까?
소리는 파동이므로 물체 경계에 부딪히면 회절, 굴절, 흡수, 감쇠를 고려해야 한다. 이후 ILD, ITD, Monaural Cues와 반사되는 소리까지 모두 계산하면 연산량이 지나치게 많아진다. 따라서 Sound Approximation (근사) 방법을 사용한다.
(1) Surround Sound 시뮬레이션하지 않고, 그냥 필터에 적용한 소리를 들려주자. 필터는 메아리 필터, 에코 필터, 반사를 줄여주는 필터, 소리를 작게 느끼게 해주는 필터, 반사돼서 들리는 소리를 느낄 수 있게 해주는 필터가 있다.
Echo 필터는 원본 소리를 시간 지연시킨 복사본을 생성한다. 이는 벽에서 반사되어 늦게 도착하는 소리를 시뮬레이션하는 것과 비슷한 효과를 얻는다.
Reverb 필터는 다양한 지연 시간과 감쇠율을 가진 여러 Echo를 합성한다. 이는 공간의 잔향(reverberation)을 시뮬레이션하는 것과 비슷한 효과를 얻는다.
즉 소리 정보를 Echo 필터 -> Reverb 필터에 적용한 결과를 사용자에게 들려주는 방법이다.
(2) HRTF(Head Related Transfer Function) Shoulder Response가 소리에 영향을 미치는 정도를 측정한 함수다. 이어폰이나 헤드폰에 적용하여 Monaural Cues를 재현한다. 표준 HRTF를 사용하면, 최소한의 하드웨어로 적당한 위치감을 제공할 수 있다.
베스트는 중요한 반사 경로(직행파 + Early Echo)는 시뮬레이션한다. 나머지 다중 반사, 회절 등은 위의 Surround Sound, HRTF 필터로 근사처리한다.